零基础写python爬虫之打包生成exe文件
1.下载pyinstaller并解压(可以去官网下载最新版):
https://github.com/pyinstaller/pyinstaller/
2.下载pywin32并安装(注意版本,我的是python2.7):
https://pypi.python.org/pypi/pywin32
3.将项目文件放到pyinstaller文件夹下面(我的是baidu.py):
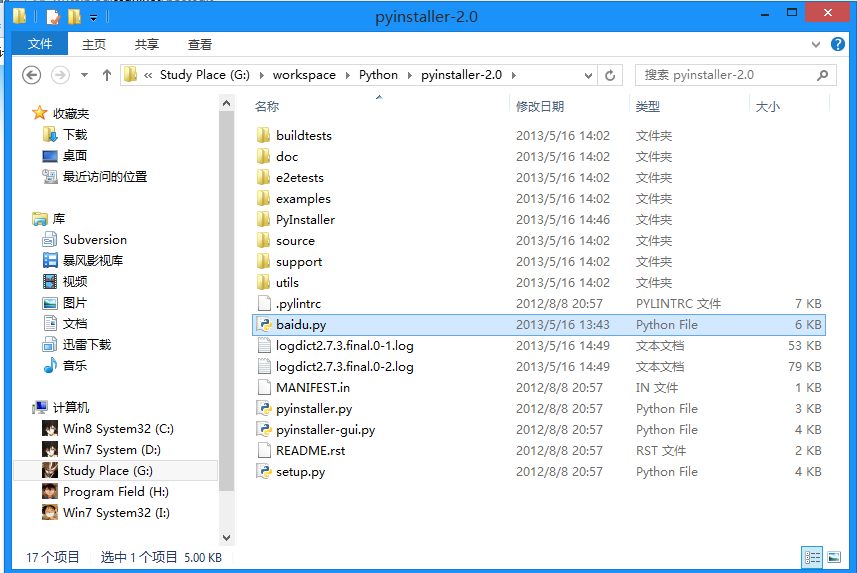
4.按住shift键右击,在当前路径打开命令提示行,输入以下内容(最后的是文件名):
python pyinstaller.py -F baidu.py
5.生成的exe文件,在baidu文件夹下的dist文件夹中,双击即可运行: