yipeiwu_com6年前
本文实例讲述了Python实现爬虫抓取与读写、追加到excel文件操作。分享给大家供大家参考,具体如下: 爬取糗事百科热门 安装 读写excel 依赖 pip install xlwt...
yipeiwu_com6年前
本文实例为大家分享了python实现爬取图书封面的具体代码,供大家参考,具体内容如下 kongfuzi.py 利用更换代理ip,延迟提交数据,设置请求头破解网站的反爬虫机制 impo...
yipeiwu_com6年前
爬取网页的流程一般如下: 选着要爬的网址(url) 使用 python 登录上这个网址(urlopen、requests 等) 读取网页信息(read() 出来) 将读...
yipeiwu_com6年前
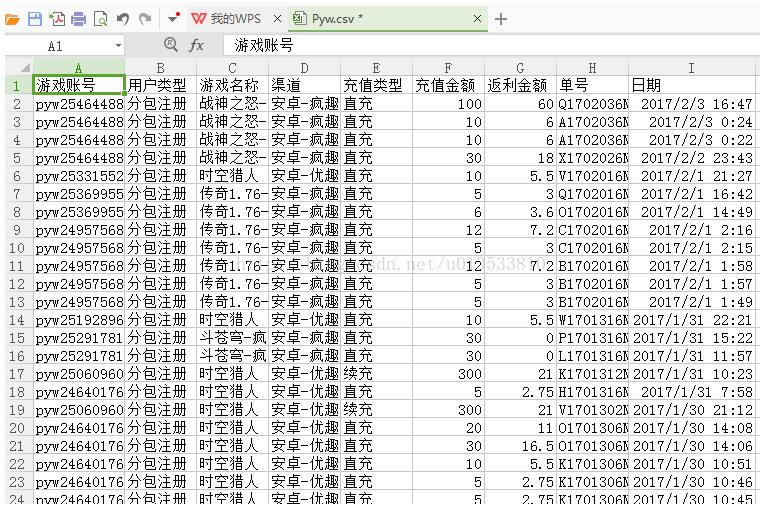
流程:模拟登录→获取Html页面→正则解析所有符合条件的行→逐一将符合条件的行的所有列存入到CSVData[]临时变量中→写入到CSV文件中 核心代码: ####写入Csv文件中...
yipeiwu_com6年前
一、利用webbrowser.open()打开一个网站: >>> import webbrowser >>> webbrowser.open('...
yipeiwu_com6年前
Urllib3是一个功能强大,条理清晰,用于HTTP客户端的Python库。许多Python的原生系统已经开始使用urllib3。Urllib3提供了很多python标准库urllib里...
yipeiwu_com6年前
本文实例讲述了Python爬虫实现简单的爬取有道翻译功能。分享给大家供大家参考,具体如下: # -*- coding:utf-8 -*- #!python3 import urlli...
yipeiwu_com6年前
本文实例为大家分享了python爬取哈尔滨天气信息的具体代码,供大家参考,具体内容如下 环境: windows7 python3.4(pip install requests;pip i...
yipeiwu_com6年前
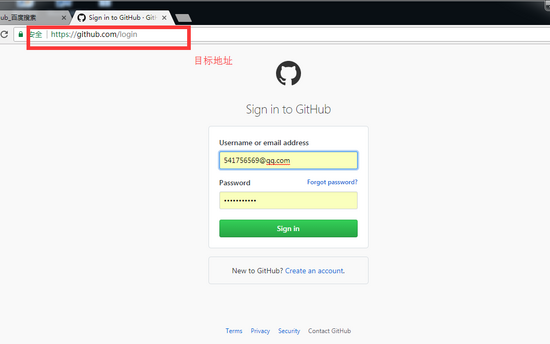
前言分析目标网站的登录方式 目标地址: https://github.com/login 登录方式做出分析: 第一,用form表单方式提交信息, 第二...
yipeiwu_com6年前
一、引入 这段时间一直在学习Python的东西,以前就听说Python爬虫多厉害,正好现在学到这里,跟着小甲鱼的Python视频写了一个爬虫程序,能实现简单的网页图片下载。 二、代码...