yipeiwu_com6年前
本文实例讲述了Python使用Selenium模块实现模拟浏览器抓取淘宝商品美食信息功能。分享给大家供大家参考,具体如下: import re from selenium impor...
yipeiwu_com6年前
本文实例讲述了Python使用Selenium模块模拟浏览器抓取斗鱼直播间信息。分享给大家供大家参考,具体如下: import time from multiprocessing i...
yipeiwu_com6年前
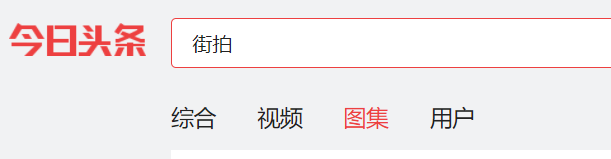
本文实例讲述了Python基于分析Ajax请求实现抓取今日头条街拍图集功能。分享给大家供大家参考,具体如下: 代码: import os import re import json...
yipeiwu_com6年前
对于大多数朋友而言,爬虫绝对是学习 python 的最好的起手和入门方式。因为爬虫思维模式固定,编程模式也相对简单,一般在细节处理上积累一些经验都可以成功入门。本文想针对某一网页对&nb...
yipeiwu_com6年前
引言 写这个小爬虫主要是为了爬校园论坛上的实习信息,主要采用了Requests库 源码 URLs.py 主要功能是根据一个初始url(包含page页面参数)来获得page页面从当前页面数...
yipeiwu_com6年前
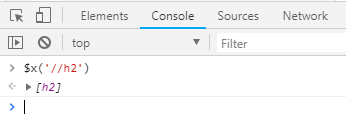
本文实例讲述了Python爬虫框架Scrapy基本用法。分享给大家供大家参考,具体如下: Xpath <html> <head> <title>...
yipeiwu_com6年前
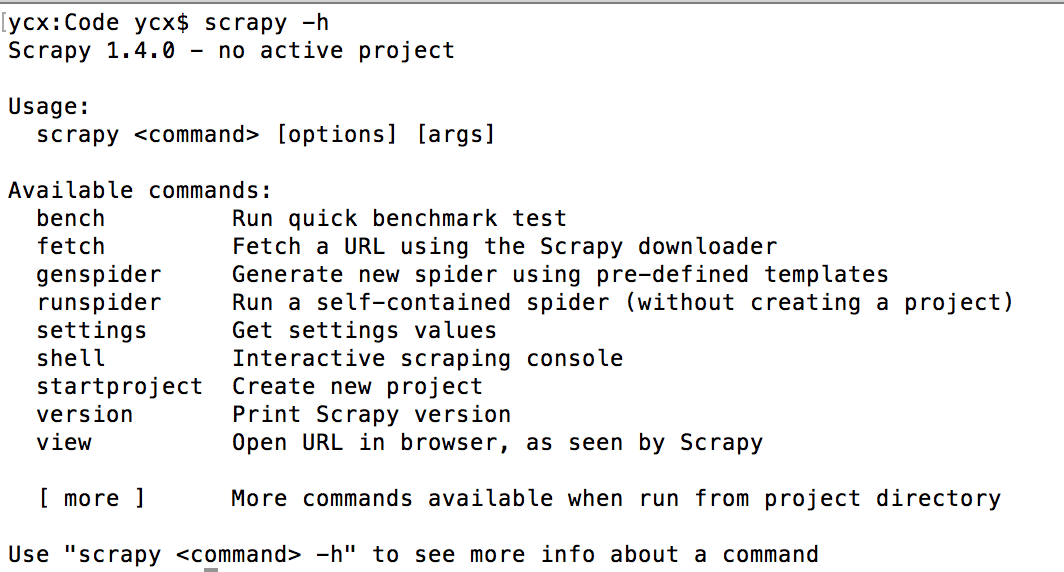
本文实例讲述了Python爬虫框架Scrapy常用命令。分享给大家供大家参考,具体如下: 在Scrapy中,工具命令分为两种,一种为全局命令,一种为项目命令。 全局命令不需要依靠Scra...
yipeiwu_com6年前
本文实例为大家分享了python使用tornado实现简单爬虫的具体代码,供大家参考,具体内容如下 代码在官方文档的示例代码中有,但是作为一个tornado新手来说阅读起来还是有点困难的...
yipeiwu_com6年前
关于这篇文章有几句话想说,首先给大家道歉,之前学的时候真的觉得下述的是比较厉害的东西,但是后来发现真的是基础中的基础,内容还不是很完全。再看一遍自己写的这篇文章,突然有种想自杀的冲动。e...
yipeiwu_com6年前
会用到的功能的简单介绍 1、from bs4 import BeautifulSoup #导入库 2、请求头herders headers={'User-Agent': 'Mo...