yipeiwu_com6年前
开发说明 开发环境:Pycharm 2017.1(目前最新) 开发框架:Scrapy 1.3.3(目前最新) 目标 爬取线报网站,并把内容保存到items.json里 页面分析...
yipeiwu_com6年前
本文实例讲述了Python正则抓取新闻标题和链接的方法。分享给大家供大家参考,具体如下: #-*-coding:utf-8-*- import re from urllib impo...
yipeiwu_com6年前
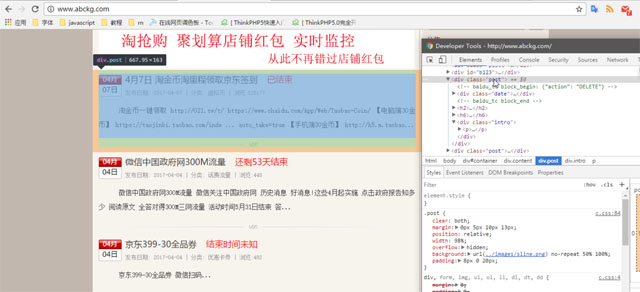
前言 本文主要介绍的是利用python爬取京东商城的方法,文中介绍的非常详细,下面话不多说了,来看看详细的介绍吧。 主要工具 scrapy BeautifulSoup r...
yipeiwu_com6年前
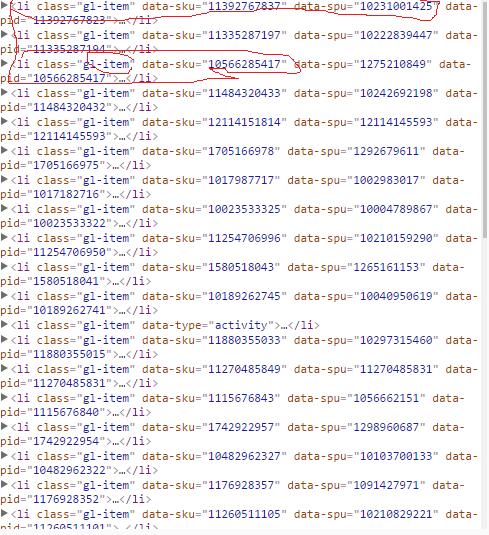
前言 之前的一篇文章已经讲过怎样获取链接,怎样获得参数了,详情请看python爬取京东商城普通篇,本文将详细介绍利用python爬虫框架scrapy如何爬取京东商城,下面话不多说了,来看...
yipeiwu_com6年前
前言 大家应该都有所体会,为了提高验证码的识别准确率,我们当然要首先得到足够多的测试数据。验证码下载下来容易,但是需要人脑手工识别着实让人受不了,于是我就想了个折衷的办法——自己造验证码...
yipeiwu_com6年前
这两天学习了python3实现抓取网页资源的方法,发现了很多种方法,所以,今天添加一点小笔记。 1、最简单 import urllib.request response = url...
yipeiwu_com6年前
本文实例讲述了Python爬虫实现网页信息抓取功能。分享给大家供大家参考,具体如下: 首先实现关于网页解析、读取等操作我们要用到以下几个模块 import urllib import...
yipeiwu_com6年前
前言 爬虫的基本原理是模拟浏览器进行 HTTP 请求,理解 HTTP 协议是写爬虫的必备基础,招聘网站的爬虫岗位也赫然写着熟练掌握HTTP协议规范,写爬虫还不得不先从HTTP协议开始讲...
yipeiwu_com6年前
前言 urllib、urllib2、urllib3、httplib、httplib2 都是和 HTTP 相关的 Python 模块,看名字就觉得很反人类,更糟糕的是这些模块在 Pytho...
yipeiwu_com6年前
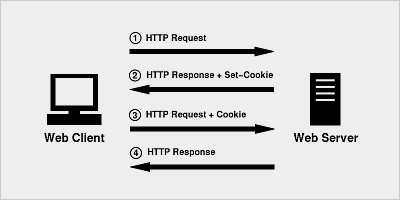
前言 对于经常写爬虫的大家都知道,有些页面在登录之前是被禁止抓取的,比如知乎的话题页面就要求用户登录才能访问,而 “登录” 离不开 HTTP 中的 Cookie 技术。 登录原理 Coo...