yipeiwu_com6年前
python 爬虫解决403禁止访问错误 在Python写爬虫的时候,html.getcode()会遇到403禁止访问的问题,这是网站对自动化爬虫的禁止,要解决这个问题,需要用到pyth...
yipeiwu_com6年前
前面我通过一篇文章讲述了如何爬取CSDN的博客摘要等信息。通常,在使用Selenium爬虫爬取数据后,需要存储在TXT文本中,但是这是很难进行数据处理和数据分析的。这篇文章主要讲述通过S...
yipeiwu_com6年前
前言 最近几天,研究了一下一直很好奇的爬虫算法。这里写一下最近几天的点点心得。下面进入正文: 你可能需要的工作环境: Python 3.6官网下载 ...
yipeiwu_com6年前
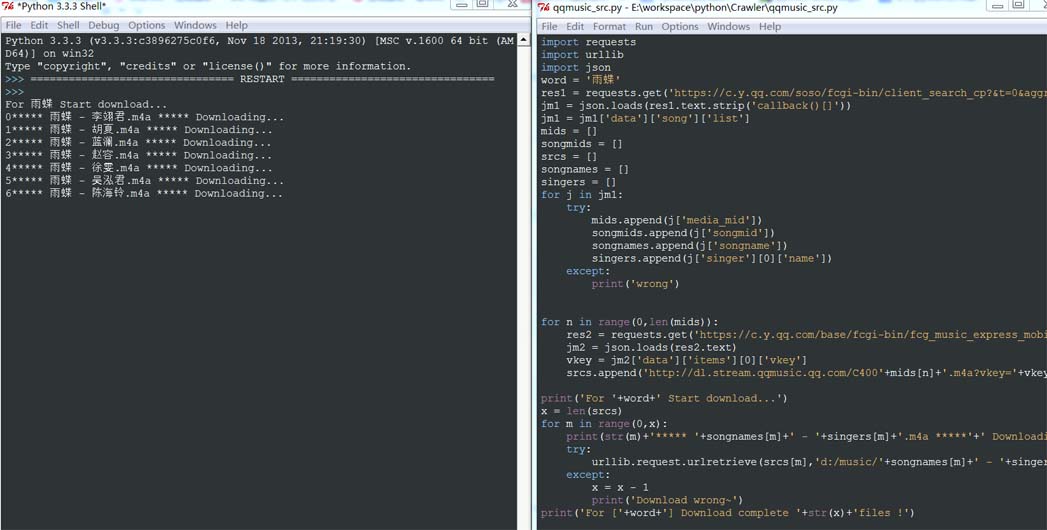
前言 qq music上的音乐还是不少的,有些时候想要下载好听的音乐,但有每次在网页下载都是烦人的登录什么的。于是,来了个qqmusic的爬虫。至少我觉得for循环爬虫,最核心的应该就是...
yipeiwu_com6年前
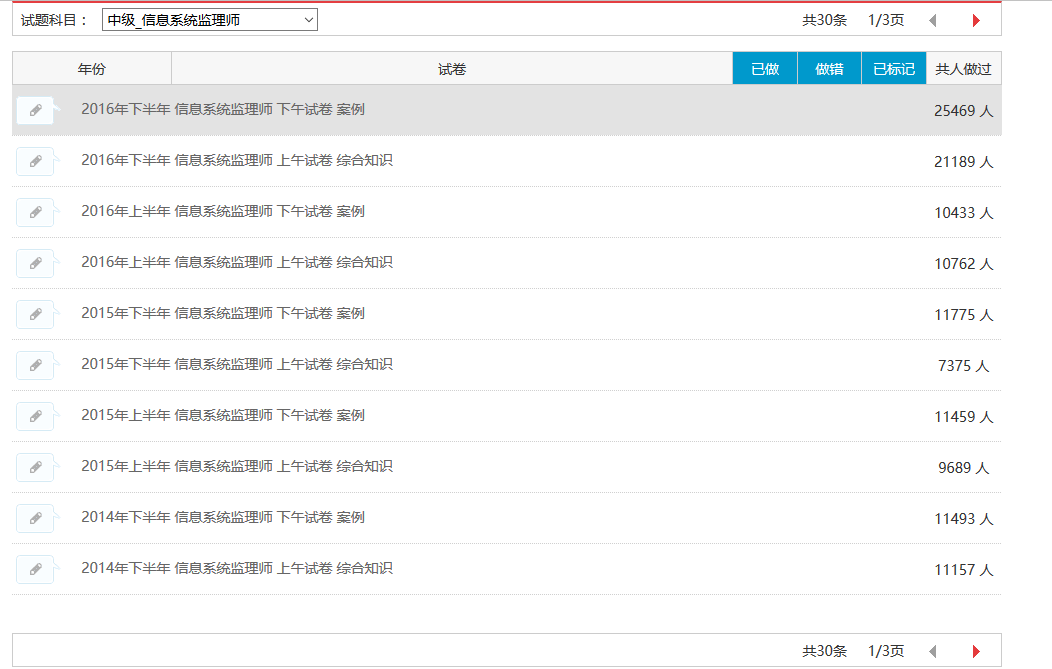
前言 最近有个软件专业等级考试,以下简称软考,为了更好的复习备考,我打算抓取www.rkpass.cn网上的软考试题。 首先讲述一下我爬取软考试题的故(keng)事(shi)。现在我已经...
yipeiwu_com6年前
最近在研究文本挖掘相关的内容,所谓巧妇难为无米之炊,要想进行文本分析,首先得到有文本吧。获取文本的方式有很多,比如从网上下载现成的文本文档,或者通过第三方提供的API进行获取数据。但是有...
yipeiwu_com6年前
最近在忙于找工作,闲暇之余,也找点爬虫项目练练手,写写代码,知道自己是个菜鸟,但是要多加练习,书山有路勤为径。各位爷有测试坑可以给我介绍个啊,自动化,功能,接口都可以做。 首先呢,我们明...
yipeiwu_com6年前
python访问抓取网页常用命令 简单的抓取网页: import urllib.request url="http://google.cn/" response=urllib....
yipeiwu_com6年前
本文实例讲述了Python使用正则表达式抓取网页图片的方法。分享给大家供大家参考,具体如下: #!/usr/bin/python import re import urllib #获...
yipeiwu_com6年前
本文实例讲述了Python正则抓取网易新闻的方法。分享给大家供大家参考,具体如下: 自己写了些关于抓取网易新闻的爬虫,发现其网页源代码与网页的评论根本就对不上,所以,采用了抓包工具得到了...