Python爬取qq music中的音乐url及批量下载
前言
qq music上的音乐还是不少的,有些时候想要下载好听的音乐,但有每次在网页下载都是烦人的登录什么的。于是,来了个qqmusic的爬虫。至少我觉得for循环爬虫,最核心的应该就是找到待爬元素所在url吧。下面开始找吧(讲的不对不要笑我)
实现如下
#寻找url:
这个url可不想其他的网站那么好找。把我给累得不轻,关键是数据多,从那么多数据里面挑出有用的数据,最后组合为music真正的music。昨天做的时候整理的几个中间url:
#url1:https://c.y.qq.com/soso/fcgi-bin/client_search_cp?&lossless=0&flag_qc=0&p=1&n=20&w=雨蝶
#url2:https://c.y.qq.com/base/fcgi-bin/fcg_music_express_mobile3.fcg?&jsonpCallback=MusicJsonCallback&cid=205361747&[songmid]&C400+songmid+.m4a&guid=6612300644
#url3:http://dl.stream.qqmusic.qq.com/[filename]?vkey=[vkey](其中vkey代替该music特有的字符串)
requests(url1)
由搜索列表得到每个音乐的的songmid和mid(通过笔者观察,这两个值是每一个music特有的)。有了这两个值。下面就得到了完整的url2的具体值。
requests(url2)
得到搜索结果中每个music的vkey值,经过笔者观察,filename即为C400songmid.m4a。进而确定了url3的具体值。而url3即为音乐的真实url,由于笔者对此url的其他参数研究的不够透彻,因此每次最多返回20首music的url,有了url,那Tencent的music就可以尽情的享受了。
#代码
下面来个srcs的代码块:
import requests
import urllib
import json
word = '雨蝶'
res1 = requests.get('https://c.y.qq.com/soso/fcgi-bin/client_search_cp?&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=20&w='+word)
jm1 = json.loads(res1.text.strip('callback()[]'))
jm1 = jm1['data']['song']['list']
mids = []
songmids = []
srcs = []
songnames = []
singers = []
for j in jm1:
try:
mids.append(j['media_mid'])
songmids.append(j['songmid'])
songnames.append(j['songname'])
singers.append(j['singer'][0]['name'])
except:
print('wrong')
for n in range(0,len(mids)):
res2 = requests.get('https://c.y.qq.com/base/fcgi-bin/fcg_music_express_mobile3.fcg?&jsonpCallback=MusicJsonCallback&cid=205361747&songmid='+songmids[n]+'&filename=C400'+mids[n]+'.m4a&guid=6612300644')
jm2 = json.loads(res2.text)
vkey = jm2['data']['items'][0]['vkey']
srcs.append('http://dl.stream.qqmusic.qq.com/C400'+mids[n]+'.m4a?vkey='+vkey+'&guid=6612300644&uin=0&fromtag=66')
#下载:
有了srcs,下载自然不成问题。当然获取歌手以及歌名也是可以把src复制到浏览器下载。也可以用大Python批量下载,无非就是一个循环,跟我们前面下载sogou图片方法类似:(笔者py版本:python3.3.3)
print('For '+word+' Start download...')
x = len(srcs)
for m in range(0,x):
print(str(m)+'***** '+songnames[m]+' - '+singers[m]+'.m4a *****'+' Downloading...')
try:
urllib.request.urlretrieve(srcs[m],'d:/music/'+songnames[m]+' - '+singers[m]+'.m4a')
except:
x = x - 1
print('Download wrong~')
print('For ['+word+'] Download complete '+str(x)+'files !')
以上两段代码,写在同一py文件,运行即可下载对应关键词的music
#运行效果:
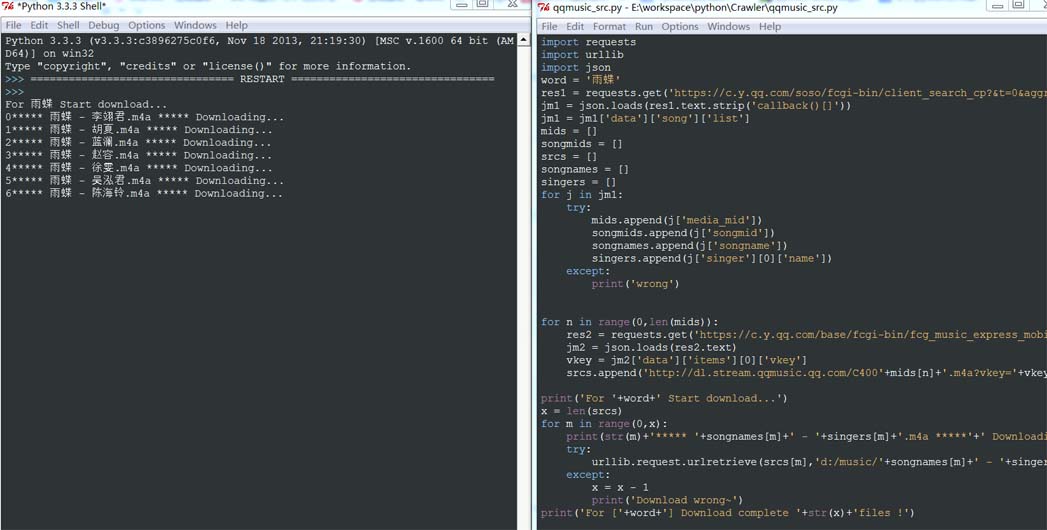
下载开始,下面...到下载目录看看:
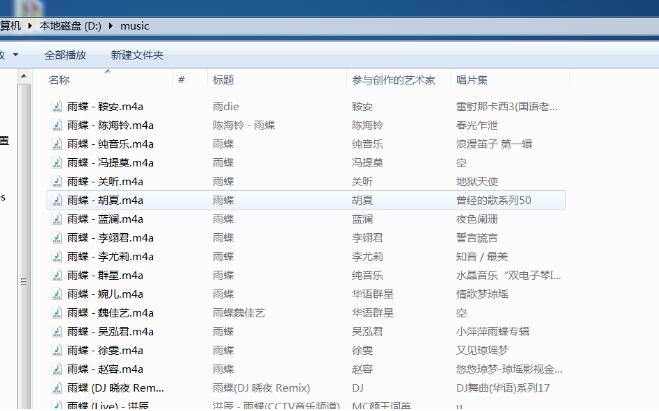
music已经成功下载。。。
至此,关于qqmusic的url爬虫程序思路及实现叙述完毕。
#用途:
musicplayer做好壳子的同学,应该用得上吧。其实做这个初衷是要为我的基于html的musicplayer服务的。但现在卡在了js调用py的环节,我再找找吧,明白的同学望告知,万分感谢!
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作能带来一定的帮助,如果有疑问大家可以留言交流,谢谢大家对【听图阁-专注于Python设计】的支持。