yipeiwu_com6年前
这篇文章主要介绍了爬虫代理池Python3WebSpider源代码测试过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 元类属性...
yipeiwu_com6年前
python是支持多线程的, 主要是通过thread和threading这两个模块来实现的,本文主要给大家分享python实现多线程网页爬虫 一般来说,使用线程有两种模式, 一种是创建线...
yipeiwu_com6年前
Selenium简介 Selenium是一个用于测试网站的自动化测试工具,支持各种浏览器包括Chrome、Firefox、Safari等主流界面浏览器,同时也支持phantomJS无界...
yipeiwu_com6年前
这篇文章主要介绍了Python scrapy增量爬取实例及实现过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 开始接触爬虫的时...
yipeiwu_com6年前
这篇文章主要介绍了python爬虫添加请求头代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 request import...
yipeiwu_com6年前
这篇文章主要介绍了python爬虫模拟浏览器访问-User-Agent过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 模拟浏览...
yipeiwu_com6年前
这篇文章主要介绍了三个python爬虫项目实例代码,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 爬取内涵段子: #encodi...
yipeiwu_com6年前
这篇文章主要介绍了Python爬虫解析网页的4种方式实例及原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 用Python写爬虫...
yipeiwu_com6年前
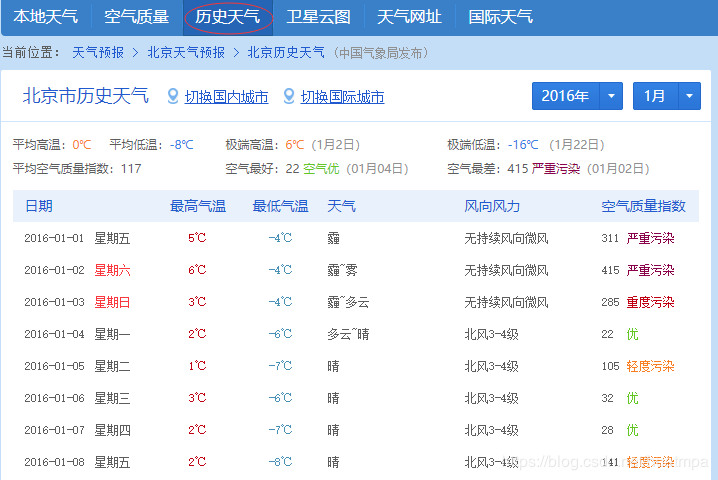
某天气网站(www.数字.com)存有2011年至今的天气数据,有天看到一本爬虫教材提到了爬取这些数据的方法,学习之,并加以改进。 准备爬的历史天气 爬之前先分析url。左上有年份、...
yipeiwu_com6年前
这篇文章主要介绍了基于python3抓取pinpoint应用信息入库,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 Pinpoint是...