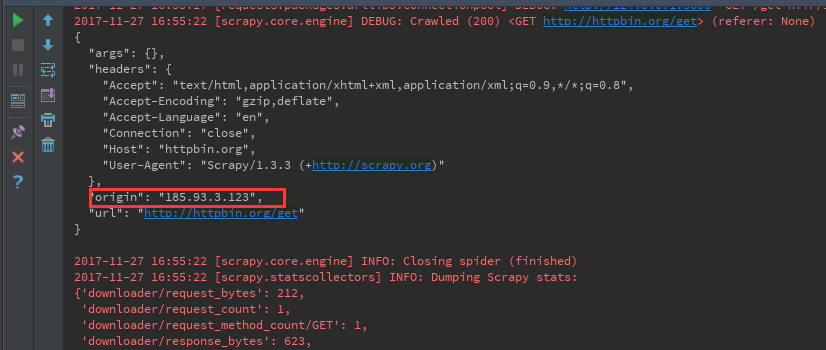
用python爬取历史天气数据的方法示例
某天气网站(www.数字.com)存有2011年至今的天气数据,有天看到一本爬虫教材提到了爬取这些数据的方法,学习之,并加以改进。
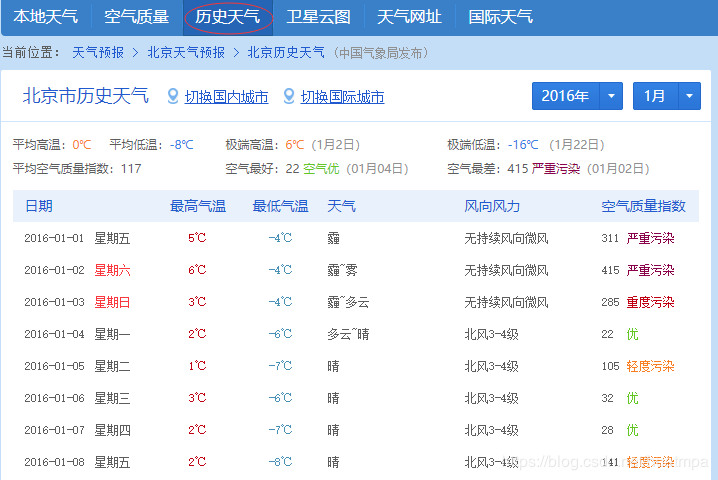
准备爬的历史天气
爬之前先分析url。左上有年份、月份的下拉选择框,按F12,进去看看能否找到真正的url:
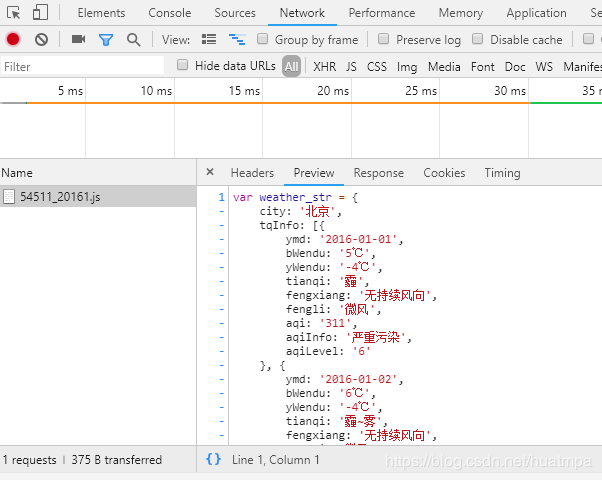
很容易就找到了,左边是储存月度数据的js文件,右边是文件源代码,貌似json格式。
双击左边js文件,地址栏内出现了url:http://tianqi.数字.com/t/wea_history/js/54511_20161.js
url中的“54511”是城市代码,“20161”是年份和月份代码。下一步就是找到城市代码列表,按城市+年份+月份构造url列表,就能开始遍历爬取了。
城市代码也很诚实,很快就找到了:
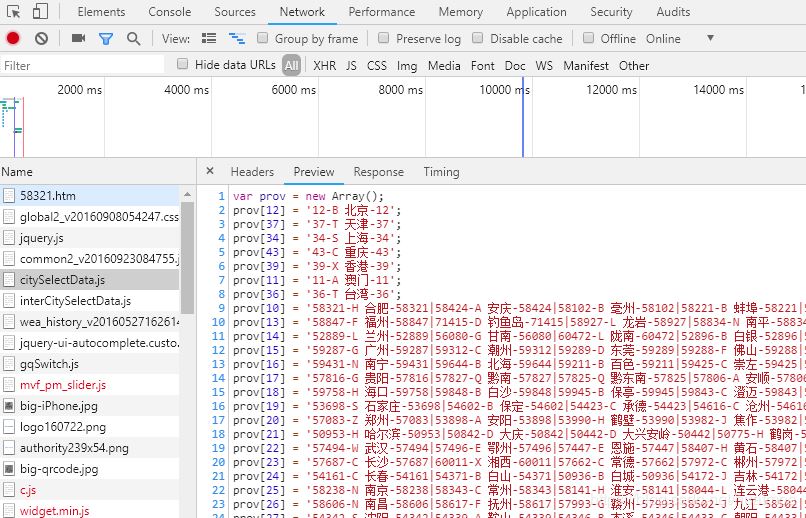
下一步得把城市名称和代码提取出来,构造一个“城市名称:城市代码”的字典,或者由元组(城市名称,城市代码)组成的列表,供爬取时遍历。考虑到正则提取时,构造元组更便捷,就不做成字典了。
def getCity():
html = reqs.get('https://tianqi.2345.com/js/citySelectData.js').content
text = html.decode('gbk')
city = re.findall('([1-5]\d{4})\-[A-Z]\s(.*?)\-\d{5}',text) #只提取了地级市及以上城市的名称和代码,5以上的是县级市
city = list(set(city)) #去掉重复城市数据
print('城市列表获取成功')
return city
接下来是构造url列表,感谢教材主编的提醒,这里避免了一个大坑。原来2017年之前的url结构和后面的不一样,在这里照搬了主编的构造方法:
def getUrls(cityCode):
urls = []
for year in range(2011,2020):
if year <= 2016:
for month in range(1, 13):
urls.append('https://tianqi.数字.com/t/wea_history/js/%s_%s%s.js' % (cityCode,year, month))
else:
for month in range(1,13):
if month<10:
urls.append('https://tianqi.数字.com/t/wea_history/js/%s0%s/%s_%s0%s.js' %(year,month,cityCode,year,month))
else:
urls.append('https://tianqi.数字.com/t/wea_history/js/%s%s/%s_%s%s.js' %(year,month,cityCode,year,month))
return urls
接下来定义一个爬取页面的函数getHtml(),这个是常规操作,用requests模块就行了:
def getHtml(url):
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:14.0) Gecko/20100101 Firefox/14.0.1',
'Referer': '******'}
request = reqs.get(url,headers = header)
text = request.content.decode('gbk') #经试解析,这里得用gbk模式
time.sleep(random.randint(1,3)) #随机暂停,减轻服务器压力
return text
然后就是重点部分了,数据解析与提取。
试了试json解析,发现效果不好,因为页面文本里面含杂质。
还是用正则表达式吧,能够提取有效数据,尽可能少浪费机器时间。
2016年开始的数据和之前年份不一样,多了PM2.5污染物情况,因此构造正则表达式时,还不能用偷懒模式。
str1 = "{ymd:'(.*?)',bWendu:'(.*?)℃',yWendu:'(.*?)℃',tianqi:'(.*?)',fengxiang:'(.*?)',fengli:'(.*?)',aqi:'(.*?)',aqiInfo:'(.*?)',aqiLevel:'(.*?)'.*?}"
str2 = "{ymd:'(.*?)',bWendu:'(.*?)℃',yWendu:'(.*?)℃',tianqi:'(.*?)',fengxiang:'(.*?)',fengli:'(.*?)'.*?}"
#这个就是偷懒模式,取出来的内容直接存入元组中
如果严格以2016年为界,用一下偷懒模式还行,但本人在这里遇坑了,原来个别城市的污染物信息是时有时无的,搞不清在某年某月的某天就出现了,因此还得构造一个通用版的,把数据都提出来,再把无用的字符去掉。
def getDf(url):
html = getHtml(url)
pa = re.compile(r'{(ymd.+?)}') #用'{ymd'打头,把不是每日天气的其它数据忽略掉
text = re.findall(pa,html)
list0 = []
for item in text:
s = item.split(',') #分割成每日数据
d = [i.split(':') for i in s] #提取冒号前后的数据名称和数据值
t = {k:v.strip("'").strip('℃') for k,v in d} #用数据名称和数据值构造字典
list0.append(t)
df = pd.DataFrame(list0) #加入pandas列表中,便于保存
return df
数据的保存,这里选择了sqlite3轻便型数据库,可以保存成db文件:
def work(city,url):
con =sql.connect('d:\\天气.db')
try:
df = getDf(url)
df.insert(0,'城市名称',city) #新增一列城市名称
df.to_sql('total', con, if_exists='append', index=False)
print(url,'下载完成')
except Exception as e:
print("出现错误:\n",e)
finally:
con.commit()
con.close()
在这里还有一个小坑,第一次连接数据库文件时,如果文件不存在,会自动添加,后续在写入数据时,如果数据中新增了字段,写入时会报错。可以先把数据库文件字段都设置好,但这样太累,所以本人又搞了个偷懒的方式,即先传入一个2019年某月的单个url搞一下,自动添加好字段,后面再写入时就没问题了。本人觉得这个应该还有更佳的解决办法,目前还在挖掘中。
数据保存后的状态如下:
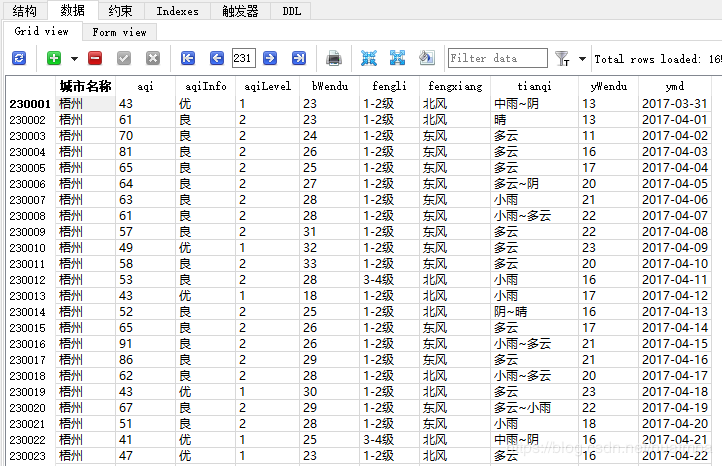
本来考虑过用多线程爬虫,想想又觉得既然人家没有设置反爬措施,咱们也不能太不厚道了,就单线程吧。
最终爬了334个城市,100多万条数据。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。