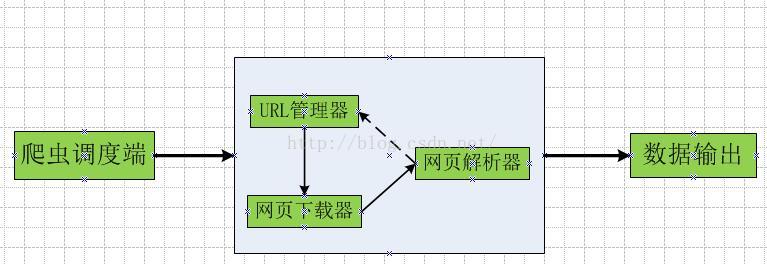
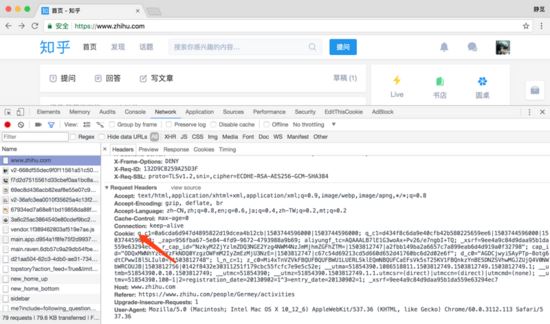
python爬虫添加请求头代码实例
这篇文章主要介绍了python爬虫添加请求头代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
request
import requests
headers = {
# 'Accept': 'application/json, text/javascript, */*; q=0.01',
# 'Accept': '*/*',
# 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-US;q=0.7',
# 'Cache-Control': 'no-cache',
# 'accept-encoding': 'gzip, deflate, br',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36',
'Referer': 'https://www.google.com/'
}
resp = requests.get('http://httpbin.org/get', headers=headers)
print(resp.content)
urllib
import urllib, urllib2
def get_page_source(url):
headers = {'Accept': '*/*',
'Accept-Language': 'en-US,en;q=0.8',
'Cache-Control': 'max-age=0',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36',
'Connection': 'keep-alive',
'Referer': 'http://www.baidu.com/'
}
req = urllib2.Request(url, None, headers)
response = urllib2.urlopen(req)
page_source = response.read()
return page_source
phantomjs请求页面
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
def get_headers_driver():
desire = DesiredCapabilities.PHANTOMJS.copy()
headers = {'Accept': '*/*',
'Accept-Language': 'en-US,en;q=0.8',
'Cache-Control': 'max-age=0',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36',
'Connection': 'keep-alive',
'Referer': 'http://www.baidu.com/'
}
for key, value in headers.iteritems():
desire['phantomjs.page.customHeaders.{}'.format(key)] = value
driver = webdriver.PhantomJS(desired_capabilities=desire, service_args=['--load-images=yes'])#将yes改成no可以让浏览器不加载图片
return driver
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。