yipeiwu_com6年前
一步一步构建一个爬虫实例,抓取糗事百科的段子 先不用beautifulsoup包来进行解析 第一步,访问网址并抓取源码 # -*- coding: utf-8 -*- # @Auth...
yipeiwu_com6年前
本文为大家分享了Python爬虫包BeautifulSoup学习实例,具体内容如下 BeautifulSoup 使用BeautifulSoup抓取豆瓣电影的一些信息。 # -*- c...
yipeiwu_com6年前
本文实例为大家分享了python爬取个性签名的具体代码,具体内容如下 #coding:utf-8 #import tkinter from tkinter import * from...
yipeiwu_com6年前
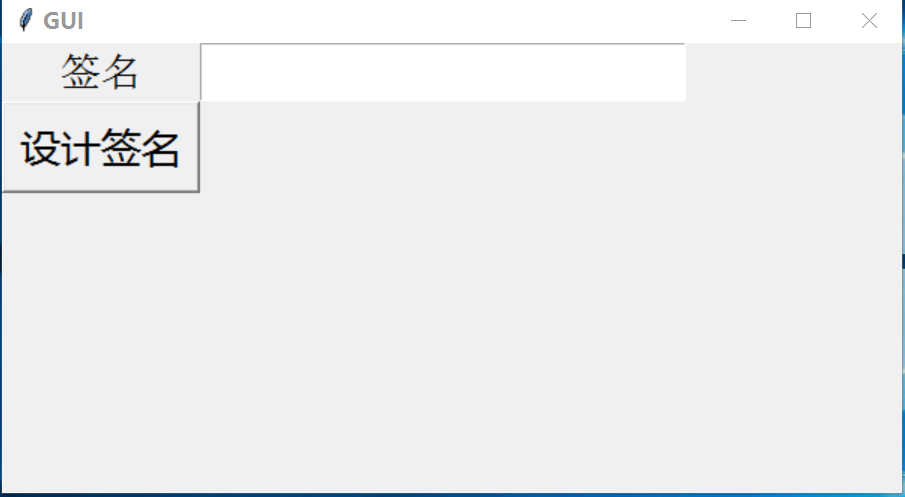
本文实例为大家分享了python3设计签名小程序的具体代码,供大家参考,具体内容如下 首先,上一下要做的效果图: 先是这样一个丑陋的界面(我尽力了的真的!) 然后随便输入名字 然后点...
yipeiwu_com6年前
思路 改进原博主文章(Python GUI–Tkinter简单实现个性签名设计)的代码,原先的代码是基于Python2的,我这份代码基于Python3 并针对当前的网站做了相应调整 前置...
yipeiwu_com6年前
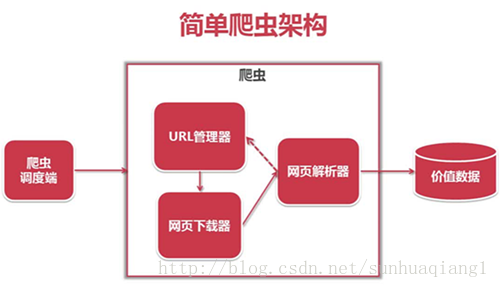
本篇博文主要讲解Python爬虫实例,重点包括爬虫技术架构,组成爬虫的关键模块:URL管理器、HTML下载器和HTML解析器。 爬虫简单架构 程序入口函数(爬虫调度段) #codi...
yipeiwu_com6年前
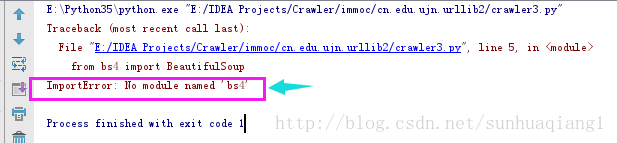
Python3安装第三方爬虫库BeautifulSoup4,供大家参考,具体内容如下 在做Python3爬虫练习时,从网上找到了一段代码如下: #使用第三方库BeautifulSou...
yipeiwu_com6年前
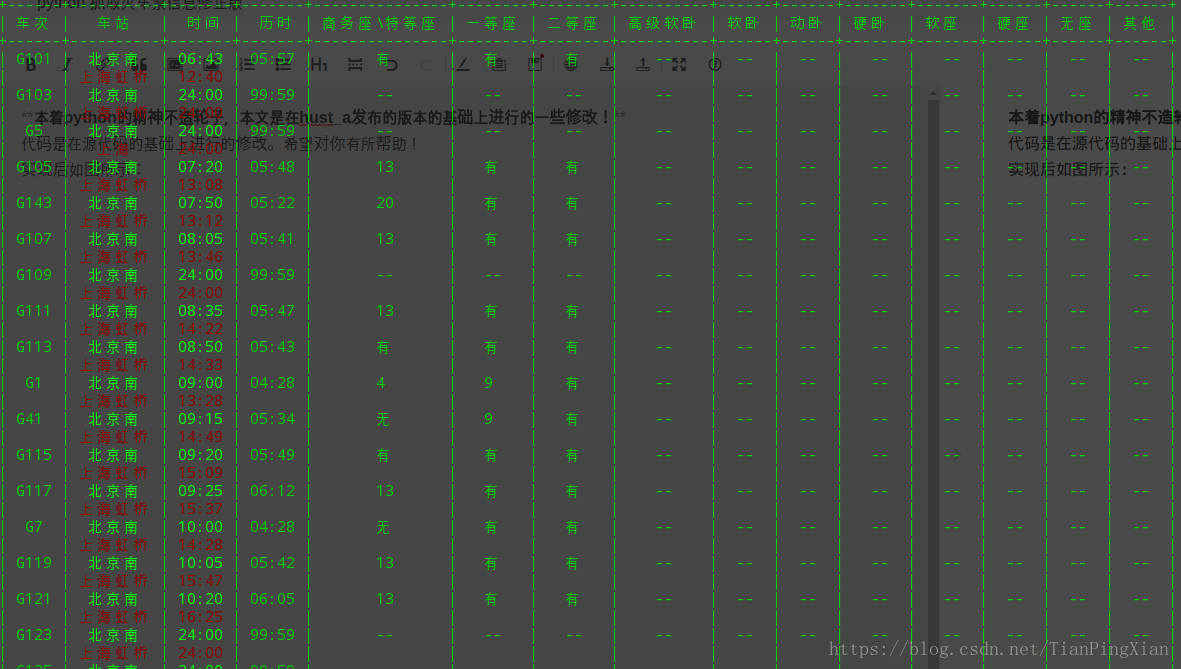
代码是在源代码的基础上进行的修改。希望对你有所帮助! 实现后如图所示: 首先我们需要抓取一些基础的数据,各大火车站信息! import urllib from urll...
yipeiwu_com6年前
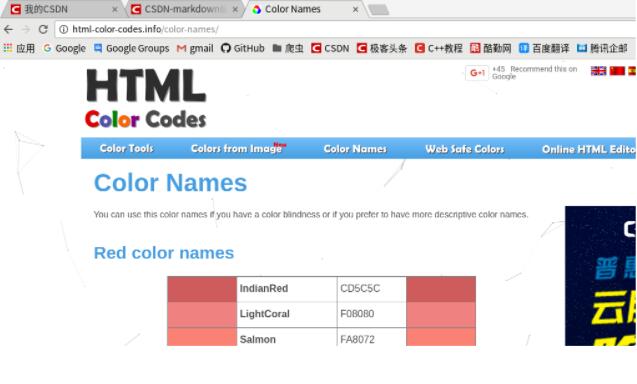
首先我们来爬取 http://html-color-codes.info/color-names/ 的一些数据。 按 F12 或 ctrl+u 审查元素,结果如下: 结构很清晰简单,...
yipeiwu_com6年前
本文实例讲述了Python基于多线程实现抓取数据存入数据库的方法。分享给大家供大家参考,具体如下: 1. 数据库类 """ 使用须知: 代码中数据表名 aces ,需要更改该数据表名...