python3.X 抓取火车票信息【修正版】
代码是在源代码的基础上进行的修改。希望对你有所帮助!
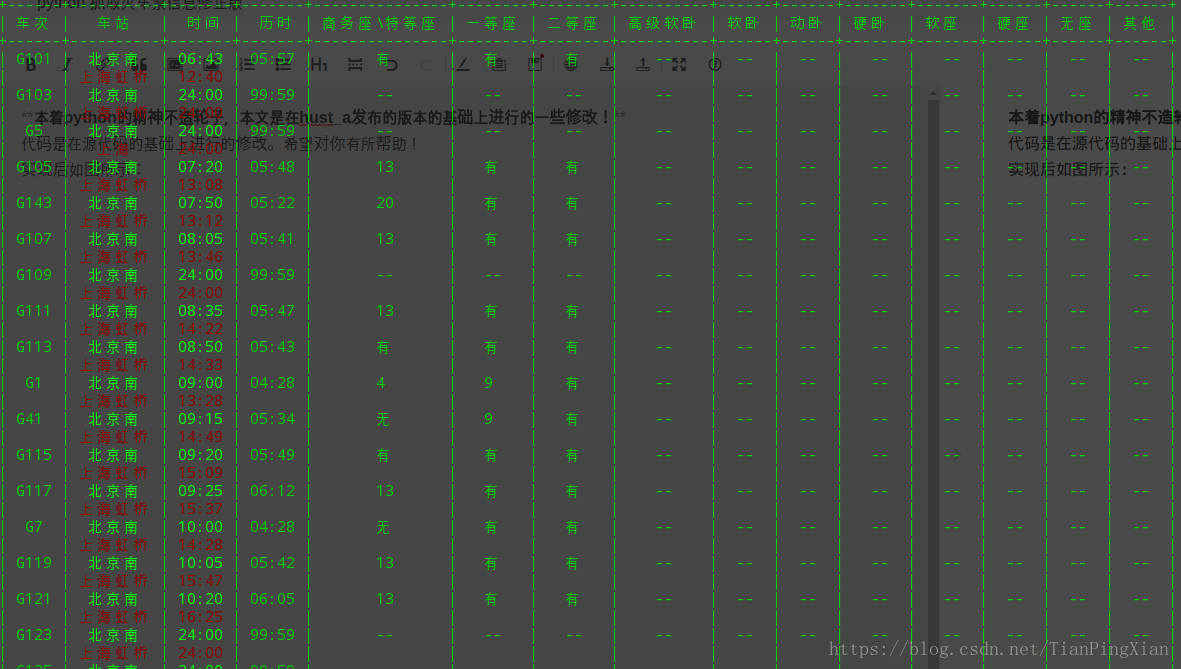
实现后如图所示:
首先我们需要抓取一些基础的数据,各大火车站信息!
import urllib
from urllib import request
import re
url = 'https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.8955'
req = urllib.request.Request(url)
r = urllib.request.urlopen(req).read().decode('utf-8')
stations = re.findall(r'([\u4e00-\u9fa5]+)|([A-Z]+)', r)
stations = dict(stations)
stations = dict(zip(stations.keys(),stations.values()))
上面的代码通过抓取,网页信息,返回一个字典数据:
stations = dict(zip(stations.keys(),stations.values()))#这行代码在后面进行了建值互换,这里没有进行过修改,这是原文的数据。
火车站的数据抓取成功,我们接下来抓取查询数据,代码如下:
from station import stations
import warnings
def change_date(d1) :
if '.' in d1 :
d1 = d1.replace('.', '-')
if not d1.startswith('0') :
d1 = str(0) + d1
if '-' in d1[-2] :
d1 = d1[:-1] + '0' + d1[-1]
return d1
def student_or_not(student) :
if 'y' in student[0].lower() :
return '0X00'
else :
return 'ADULT'
f1 = input('请输入开始城市:\n')
f = stations[f1]
t1 = input('请输入目的城市:\n')
t = stations[t1]
d1 = input('请输入出发时间:\n')
d = str('2018-') + change_date(d1)
student = input('是否为学生票,输入(yes/no)')
print('正在查询' + f1 + '至' + t1 + '的列车,请听听音乐......')
url = 'https://kyfw.12306.cn/otn/leftTicket/query?leftTicketDTO.train_date={d}&leftTicketDTO.from_station={f}&leftTicketDTO.to_station={t}&purpose_codes={student}'
url = url.format(f=f, d=d, t=t, student=student_or_not(student))
warnings.filterwarnings("ignore")
这里本人增加了两个函数 change_date() 和 student_or_not()
change_date() 这个函数对用户输入日期的行为进行了简化,提高了用户体验,可以直接输入比如7.3这样的日期,其他的符号,我们可以自己进行扩展。
student_or_not() 这个函数的作用是判断查询的是普通票还是学生票
美化显示,区分到站和出发站点的颜色,我们加入如下函数
def colored(color, text) :
table = {
'red' : '\033[91m',
'green' : '\033[92m',
'nc' : '\033[0m'
}
cv = table.get(color)
nc = table.get('nc')
return ''.join([cv, text, nc])
最后我们进行数据处理展示:
import requests
from get_urltrain import url
from prettytable import PrettyTable
from color_set import colored
from station import stations
def chair_lists(row_list) :
chair_list = []
for i in range(len(row_list) - 5, 21, -1) :
if row_list[i] != '' :
chair_list.append(row_list[i])
else :
chair_list.append('--')
return chair_list
headers = {
'user-agent' : 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36'
}
r = requests.get(url, verify=False, headers=headers) # 请求网址1的内容
rows = r.json()['data']['result'] # 将内容解析为列表
trains = PrettyTable()
trains.field_names = ["车次", "车站", "时间", "历时", "商务座\特等座", "一等座", "二等座", "高级软卧", "软卧", "动卧", "硬卧 ", "软座 ", "硬座", "无座",
"其他"]
# 设置table的header
num = len(rows) # 打印列表的个数
# station1 = dict([v, k] for k, v in stations.items())
station_list = dict(zip(stations.values(), stations.keys()))
for row in rows : # 列表循环
row_list = row.split('|')
chair_list = chair_lists(row_list)
trains.add_row([row_list[3],
'\n'.join([colored('green', station_list[row_list[6]]),
colored('red', station_list[row_list[7]])]),
'\n'.join([colored('green', row_list[8]),
colored('red', row_list[9])]),
row_list[10],
] + chair_list)
print('查询结束,共有 %d 趟列车。' % num) # 列表个数也就是列车个数
print(trains)
这里我增加了 chair_lists()函数进行循环处理对应的表段
用于空数据替换成‘–'
station_list = dict(zip(stations.values(), stations.keys()))
#station_list 进行了建值互换方便下面的循环中的调用
trains.add_row([row_list[3],
'\n'.join([colored('green', station_list[row_list[6]]),
colored('red', station_list[row_list[7]])]),
'\n'.join([colored('green', row_list[8]),
colored('red', row_list[9])]),
row_list[10],
] + chair_list)
这个抓取案例我们可以举一反三,可以拓展很多功能,方便我们进行数据快速查询,比如展示价格等等!
源代码在:https://github.com/morganlions/train
总结
以上所述是小编给大家介绍的python3.X 抓取火车票信息【修正版】,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对【听图阁-专注于Python设计】网站的支持!