简单实现Python爬取网络图片
本文实例为大家分享了Python爬取网络图片的具体代码,供大家参考,具体内容如下
代码:
import urllib
import urllib.request
import re
#打开网页,下载器
def open_html ( url):
require=urllib.request.Request(url)
reponse=urllib.request.urlopen(require)
html=reponse.read()
return html
#下载图片
def load_image(html):
regx='http://[\S]*jpg'
pattern=re.compile(regx)
get_image=re.findall(pattern,repr(html))
num=1
for img in get_image:
photo=open_html(img)
with open(r'E:\Photo\%s.jpg'%num,'wb') as f:
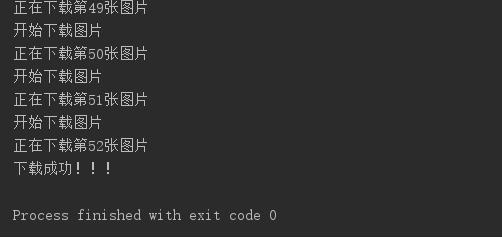
print('开始下载图片')
f.write(photo)
print('正在下载第%s张图片'%num)
f.close()
num=num+1
if num>1:
print('下载成功!!!')
else:
print('下载失败!!!')
url='http://www.qiqipu.com/'
html=open_html(url)
load_image(html)
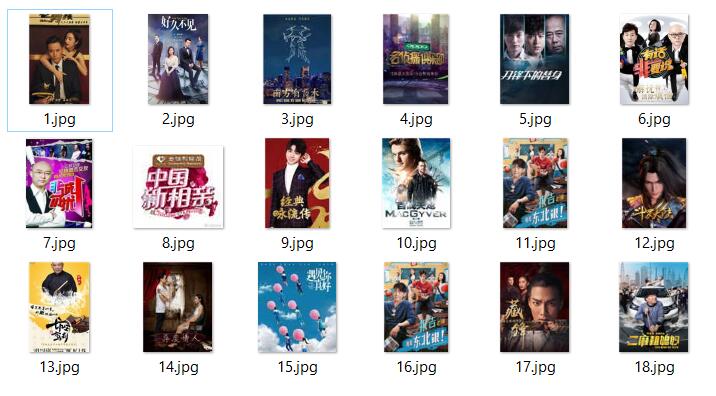
执行结果:
注意:
在运行之前,必须要有路径(文件夹):E:\Photo\
如果网站是HTTPS可以将正则中的http换为HTTPS,可以再定义一个下载图片的函数
如果想要下载jpg、png、gif等多种格式的图片可以将正则中的jpg换为对应格式,也可以使用元组定义多种格式后遍历
我这里只要jpg就可以,就不改了,大家可以自己改下。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。