yipeiwu_com6年前
本文主要分享关于python登录并爬取淘宝信息的相关代码,还是挺不错的,大家可以了解下。 #!/usr/bin/env python # -*- coding:utf-8 -*-...
yipeiwu_com6年前
本代码主要实现抓取大众点评网中关村附近的餐馆有哪些,具体如下: import urllib.request import re def fetchFood(url): #...
yipeiwu_com6年前
爬虫与反爬虫,这相爱相杀的一对,简直可以写出一部壮观的斗争史。而在大数据时代,数据就是金钱,很多企业都为自己的网站运用了反爬虫机制,防止网页上的数据被爬虫爬走。然而,如果反爬机制过于严格...
yipeiwu_com6年前
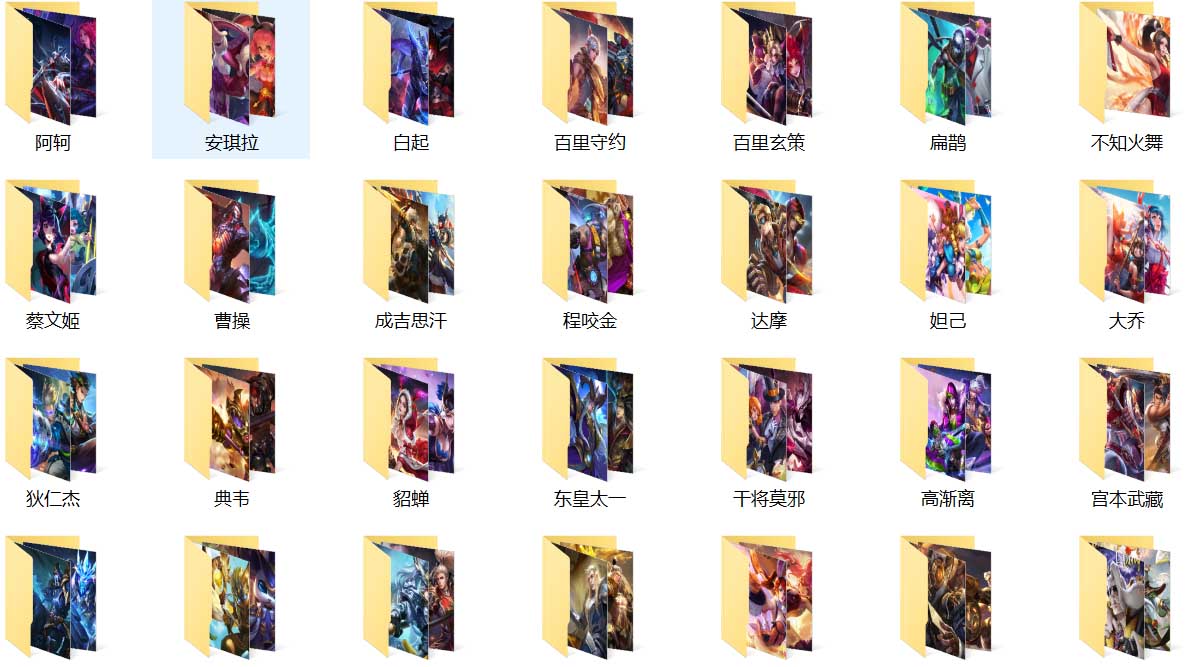
本文使用python的第三方模块requests爬取王者荣耀所有英雄的图片,并将图片按每个英雄为一个目录存入文件夹中,方便用作桌面壁纸 下面时具体的代码,已通过python3.6测试,可...
yipeiwu_com6年前
多线程爬虫:即程序中的某些程序段并行执行, 合理地设置多线程,可以让爬虫效率更高 糗事百科段子普通爬虫和多线程爬虫 分析该网址链接得出: https://www.qiushibaike....
yipeiwu_com6年前
利用python抓取网络图片的步骤是: 1、根据给定的网址获取网页源代码 2、利用正则表达式把源代码中的图片地址过滤出来 3、根据过滤出来的图片地址下载网络图片 以下是比较简单的一个抓取...
yipeiwu_com6年前
既然本篇文章说到的是Python构建网页爬虫原理分析,那么小编先给大家看一下Python中关于爬虫的精选文章: python实现简单爬虫功能的示例 python爬虫实战之最简单的网页爬虫...
yipeiwu_com6年前
题记:早已听闻python爬虫框架的大名。近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享。有表述不当之处,望大神们斧正。 一、初窥Scrapy Scrapy是一个为了爬...
yipeiwu_com6年前
需要准备的环境: 一个B站账号,需要先登录,否则不能查看历史弹幕记录 联网的电脑和顺手的浏览器,我用的Chrome Python3环境以及request模块,安装使用命令,换源比较快:...
yipeiwu_com6年前
本文介绍了Python数据抓取分析,分享给大家,具体如下: 编程模块:requests,lxml,pymongo,time,BeautifulSoup 首先获取所有产品的分类网址:...