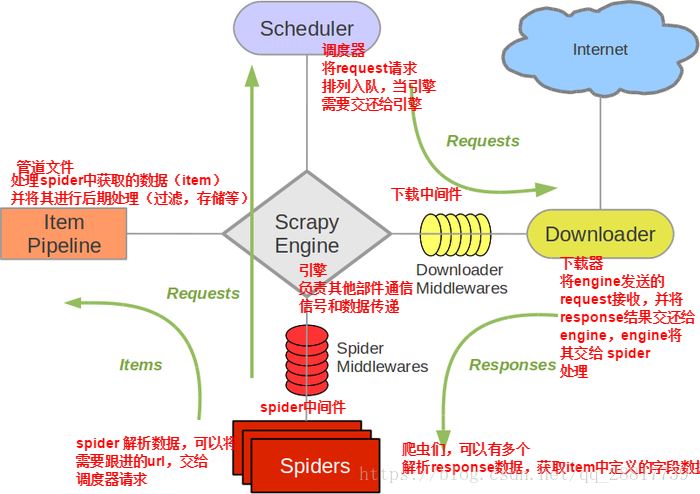
python抓取京东价格分析京东商品价格走势
from creepy import Crawler
from BeautifulSoup import BeautifulSoup
import urllib2
import json
class MyCrawler(Crawler):
def process_document(self, doc):
if doc.status == 200:
print '[%d] %s' % (doc.status, doc.url)
try:
soup = BeautifulSoup(doc.text.decode('gb18030').encode('utf-8'))
except Exception as e:
print e
soup = BeautifulSoup(doc.text)
print soup.find(id="product-intro").div.h1.text
url_id=urllib2.unquote(doc.url).decode('utf8').split('/')[-1].split('.')[0]
f = urllib2.urlopen('http://p.3.cn/prices/get?skuid=J_'+url_id,timeout=5)
price=json.loads(f.read())
f.close()
print price[0]['p']
else:
pass
crawler = MyCrawler()
crawler.set_follow_mode(Crawler.F_SAME_HOST)
crawler.set_concurrency_level(16)
crawler.add_url_filter('\.(jpg|jpeg|gif|png|js|css|swf)$')
crawler.crawl('http://item.jd.com/982040.html')