Fiddler如何抓取手机APP数据包
Fiddler,这个是所有软件开发者必备神器!这款工具不仅可以抓取PC上开发web时候的数据包,而且可以抓取移动端(Android,Iphone,WindowPhone等都可以)。
第一步:下载神器Fiddler,下载链接:
http://w.x.baidu.com/alading/anquan_soft_down_ub/10963
下载完成之后,傻瓜式的安装一下了!
第二步:设置Fiddler
打开Fiddler, Tools-> Fiddler Options (配置完后记得要重启Fiddler)
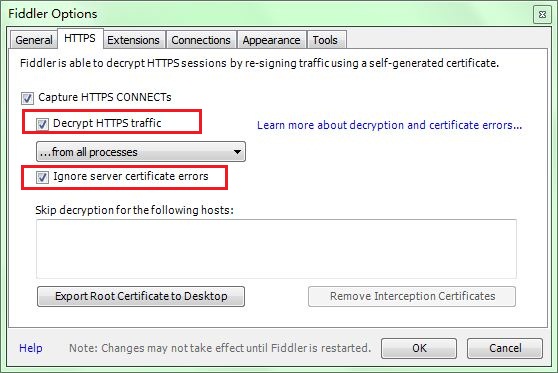
选中"Decrpt HTTPS traffic", Fiddler就可以截获HTTPS请求
选中"Allow remote computers to connect". 是允许别的机器把HTTP/HTTPS请求发送到Fiddler上来
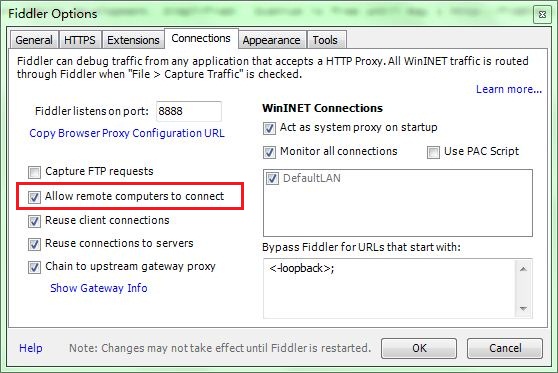
记住这个端口号是:8888
第三步:设置Android手机
首先获取PC的ip地址:命令行中输入:ipconfig,获取ip地址
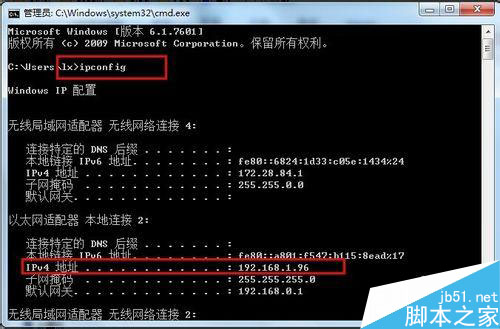
好吧,这时候我就拿到了IP地址和端口号了
下面来对Android手机进行代理设置
确定一下手机和PC是连接在同一个局域网中
进入手机的设置->点击进入WLAN设置->选择连接到的无线网,长按弹出选项框:如图所示:
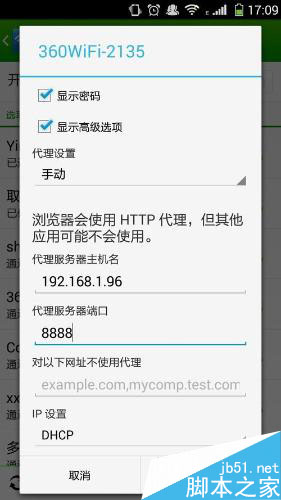
将代理设置成手动,将上面获取到的ip地址和端口号填入,点击保存。这样就将我们的手机设置成功了。
第四步:下载Fiddler的安全证书
使用Android手机的浏览器打开:http://192.168.1.96:8888, 点"FiddlerRoot certificate" 然后安装证书,如图:

到这里我们就设置好所有的值,下面就来测试一下,打开手机的超级课程表APP
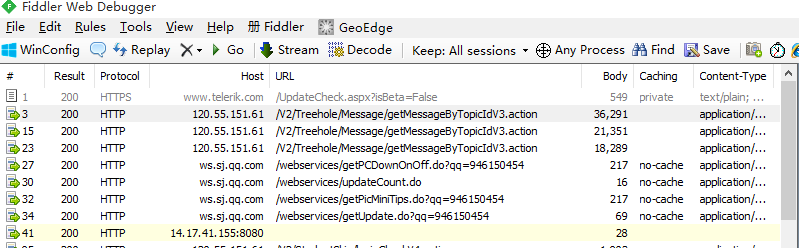
这样就抓取Android移动端的数据包成功了,这个对于我们后面进行网络数据请求的调试有很大的帮助,我们可以通过这个方法来判断我们请求网络是否成功!