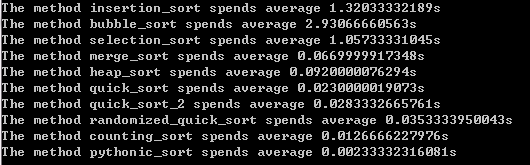
python实现聚类算法原理
本文主要内容:
- 聚类算法的特点
- 聚类算法样本间的属性(包括,有序属性、无序属性)度量标准
- 聚类的常见算法,原型聚类(主要论述K均值聚类),层次聚类、密度聚类
- K均值聚类算法的python实现,以及聚类算法与EM最大算法的关系
- 参考引用
先上一张gif的k均值聚类算法动态图片,让大家对算法有个感性认识:
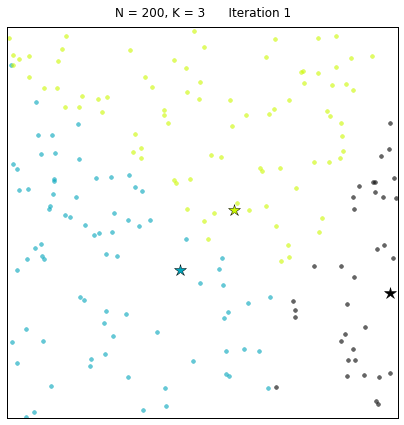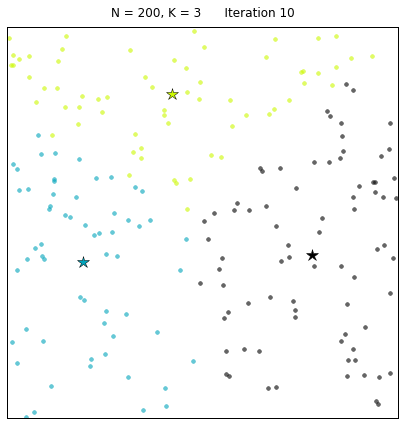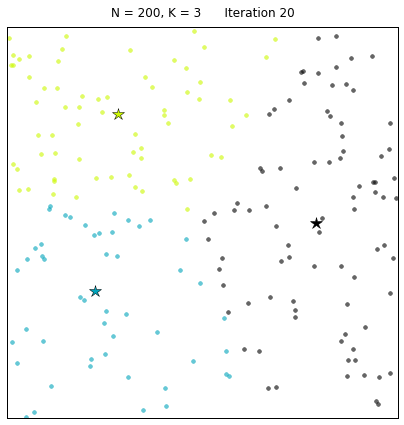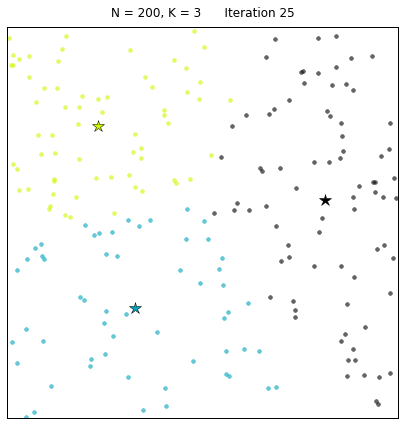
其中:N=200代表有200个样本,不同的颜色代表不同的簇(其中 3种颜色为3个簇),星星代表每个簇的簇心。算法通过25次迭代找到收敛的簇心,以及对应的簇。 每次迭代的过程中,簇心和对应的簇都在变化。
聚类算法的特点
聚类算法是无监督学习算法和前面的有监督算法不同,训练数据集可以不指定类别(也可以指定)。聚类算法对象归到同一簇中,类似全自动分类。簇内的对象越相似,聚类的效果越好。K-均值聚类是每个类别簇都是采用簇中所含值的均值计算而成。

聚类样本间的属性(包括,有序属性、无序属性)度量标准 1. 有序属性
例如:西瓜的甜度:0.1, 0.5, 0.9(值越大,代表越甜)
我们可以使用明可夫斯基距离定义:

2. 无序属性
例如:色泽,青绿、浅绿、深绿(又例如: 性别: 男, 女, 中性,人yao…明显也不能使用0.1, 0.2 等表示求距离)。这些不能使用连续的值表示,求距离的,一般使用VDM计算:


聚类的常见算法,原型聚类(主要论述K均值聚类),层次聚类、密度聚类
聚类算法分为如下三大类:
1. 原型聚类(包含3个子类算法):
K均值聚类算法
学习向量量化
高斯混合聚类
2. 密度聚类:
3. 层次聚类:
下面主要说明K均值聚类算法(示例来源于,周志华西瓜书)
算法基本思想:
K-Means 是发现给定数据集的 K 个簇的聚类算法, 之所以称之为 K-均值 是因为它可以发现 K 个不同的簇,且每个簇的中心采用簇中所含值的均值计算而成.簇个数 K 是用户指定的, 每一个簇通过其质心(centroid), 即簇中所有点的中心来描述.
算法流程如下:

主要是三个步骤:
- 初始化选择K个簇心,假设样本有 m个属性,则相当于k个m为向量
- 对于k个簇,求离其最近的样本,并划分新的簇
- 对于每个新的簇,更新簇心的向量(一般可以求簇的样本的属性的均值)
- 重复2~3直到算法收敛,或者运行了指定的次数
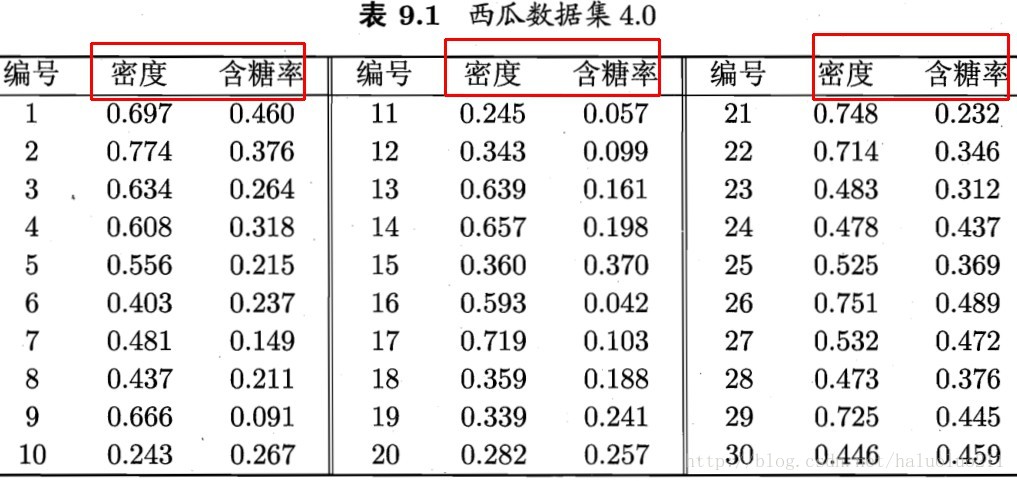
下面给出西瓜书的示例:
西瓜包含下面两个属性,密度以及含糖率,这两个属性构成的二维向量,作为输入向量(具体数据如下表)
算法大致过程如下:

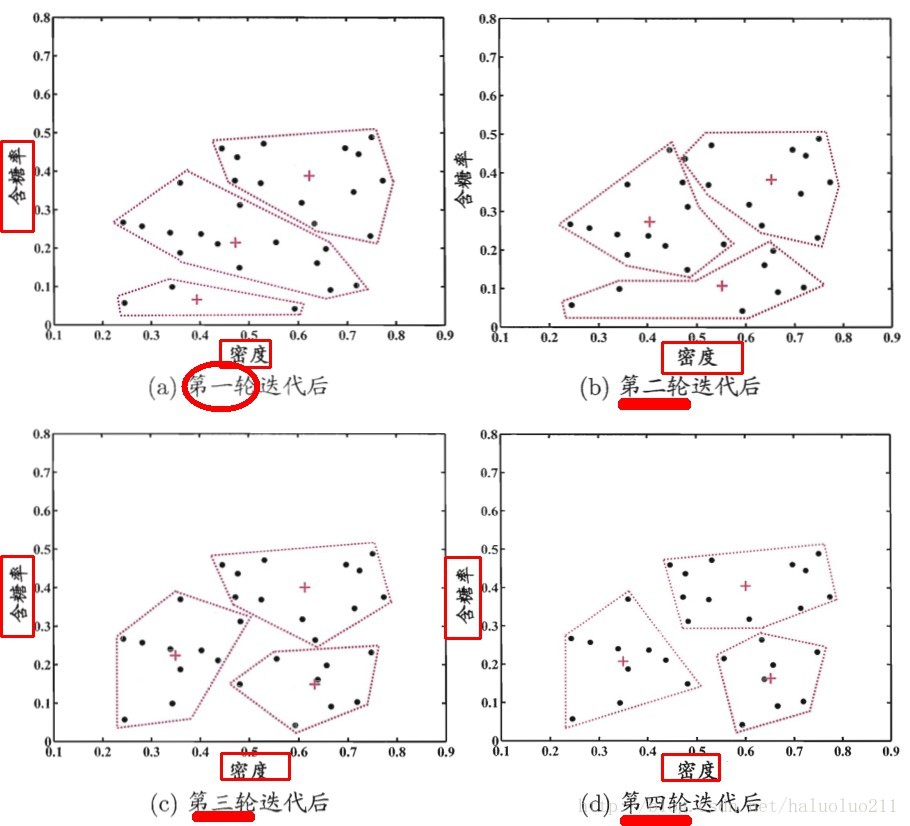
下图是分类的,每一轮簇心的更新结果,图中横坐标为密度属性,纵坐标为含糖率属性:
4. K均值聚类算法的python实现
下面给出K-means cluster算法的实现的大致框架:
class KMeans(object):
def __init__(self, k, init_vec, max_iter=100):
"""
:param k:
:param init_vec: init mean vectors type: k * n array(n properties)
"""
self._k = k
self._cluster_vec = init_vec
self._max_iter = max_iter
def fit(self, x):
# 迭代最大次数
for i in xrange(self._max_iter):
print 'iteration %s' % i
# 求每个簇心的簇类
d_cluster = self._cluster_point(x)
# 对现有的簇类,更新簇心
new_center_node = self._reevaluate_center_node(d_cluster)
# 检测簇心是否变化,判断算法收敛
if self._check_converge(new_center_node):
print 'found converge node'
break
else:
self._cluster_vec = new_center_node
def _cal_distance(self, vec1, vec2):
return np.linalg.norm(vec1 - vec2)
def _cluster_point(self, x):
# 求每个簇心的簇
pass
return d_cluster
def _reevaluate_center_node(self, d_cluster):
# 对新的簇,求最佳簇心
return arr_center_node
def _check_converge(self, vec):
# 判断簇心是否改变,算法收敛
return np.array_equal(self._cluster_vec, vec)
具体的算法,以及见本人的github
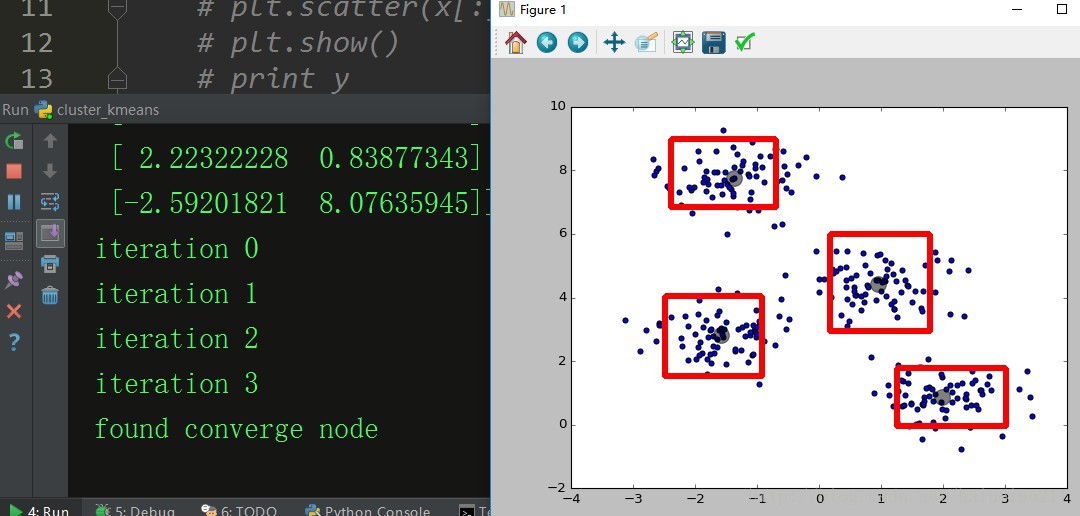
下面给出程序的运行结果, 由图可见经过三次迭代程序收敛,并且找到最佳节点:
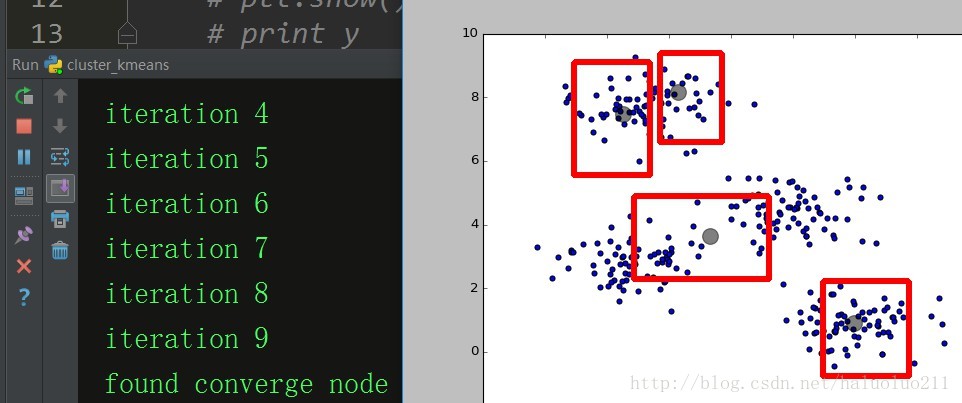
下面再给出,另一次运行结果,可见由于初始化点选择不一样,得到的结果也是不一样的,初始点的选择对聚类算法的影响还是很大。
K-means实际上是EM算法的一个特例,根据中心点(簇心)决定数据点归属是expectation,而根据构造出来的cluster更新中心(簇心)则是maximization。理解了K-means,也就顺带了解了基本的EM算法思路。
5. 参考引用
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。