python实现SOM算法
算法简介
SOM网络是一种竞争学习型的无监督神经网络,将高维空间中相似的样本点映射到网络输出层中的邻近神经元。
训练过程简述:在接收到训练样本后,每个输出层神经元会计算该样本与自身携带的权向量之间的距离,距离最近的神经元成为竞争获胜者,称为最佳匹配单元。然后最佳匹配单元及其邻近的神经元的权向量将被调整,以使得这些权向量与当前输入样本的距离缩小。这个过程不断迭代,直至收敛。
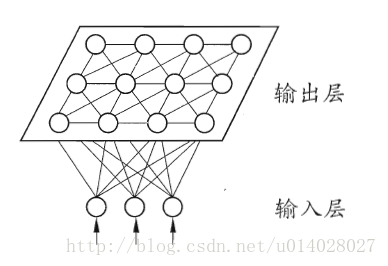
- 网络结构:输入层和输出层(或竞争层),如下图所示。
- 输入层:假设一个输入样本为X=[x1,x2,x3,…,xn],是一个n维向量,则输入层神经元个数为n个。
- 输出层(竞争层):通常输出层的神经元以矩阵方式排列在二维空间中,每个神经元都有一个权值向量。
- 假设输出层有m个神经元,则有m个权值向量,Wi = [wi1,wi2,....,win], 1<=i<=m。
算法流程:
1. 初始化:权值使用较小的随机值进行初始化,并对输入向量和权值做归一化处理
X' = X/||X||
ω'i= ωi/||ωi||, 1<=i<=m
||X||和||ωi||分别为输入的样本向量和权值向量的欧几里得范数。
2.将样本输入网络:样本与权值向量做点积,点积值最大的输出神经元赢得竞争,
(或者计算样本与权值向量的欧几里得距离,距离最小的神经元赢得竞争)记为获胜神经元。
3.更新权值:对获胜的神经元拓扑邻域内的神经元进行更新,并对学习后的权值重新归一化。
ω(t+1)= ω(t)+ η(t,n) * (x-ω(t))
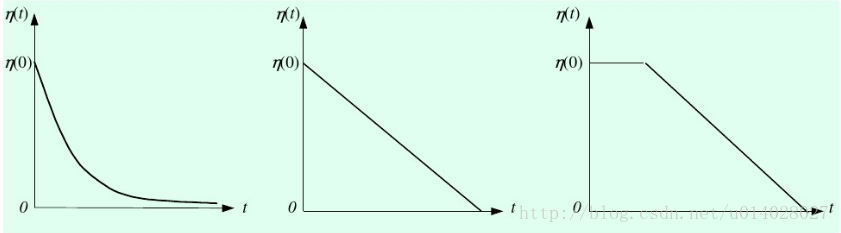
η(t,n):η为学习率是关于训练时间t和与获胜神经元的拓扑距离n的函数。
η(t,n)=η(t)e^(-n)
η(t)的几种函数图像如下图所示。
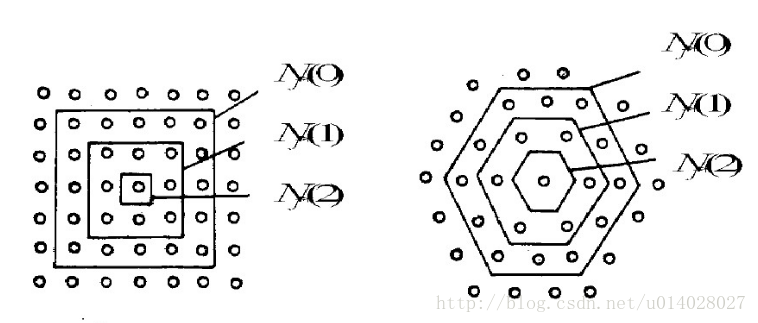
4.更新学习速率η及拓扑邻域N,N随时间增大距离变小,如下图所示。
5.判断是否收敛。如果学习率η<=ηmin或达到预设的迭代次数,结束算法。
python代码实现SOM
import numpy as np
import pylab as pl
class SOM(object):
def __init__(self, X, output, iteration, batch_size):
"""
:param X: 形状是N*D, 输入样本有N个,每个D维
:param output: (n,m)一个元组,为输出层的形状是一个n*m的二维矩阵
:param iteration:迭代次数
:param batch_size:每次迭代时的样本数量
初始化一个权值矩阵,形状为D*(n*m),即有n*m权值向量,每个D维
"""
self.X = X
self.output = output
self.iteration = iteration
self.batch_size = batch_size
self.W = np.random.rand(X.shape[1], output[0] * output[1])
print (self.W.shape)
def GetN(self, t):
"""
:param t:时间t, 这里用迭代次数来表示时间
:return: 返回一个整数,表示拓扑距离,时间越大,拓扑邻域越小
"""
a = min(self.output)
return int(a-float(a)*t/self.iteration)
def Geteta(self, t, n):
"""
:param t: 时间t, 这里用迭代次数来表示时间
:param n: 拓扑距离
:return: 返回学习率,
"""
return np.power(np.e, -n)/(t+2)
def updata_W(self, X, t, winner):
N = self.GetN(t)
for x, i in enumerate(winner):
to_update = self.getneighbor(i[0], N)
for j in range(N+1):
e = self.Geteta(t, j)
for w in to_update[j]:
self.W[:, w] = np.add(self.W[:,w], e*(X[x,:] - self.W[:,w]))
def getneighbor(self, index, N):
"""
:param index:获胜神经元的下标
:param N: 邻域半径
:return ans: 返回一个集合列表,分别是不同邻域半径内需要更新的神经元坐标
"""
a, b = self.output
length = a*b
def distence(index1, index2):
i1_a, i1_b = index1 // a, index1 % b
i2_a, i2_b = index2 // a, index2 % b
return np.abs(i1_a - i2_a), np.abs(i1_b - i2_b)
ans = [set() for i in range(N+1)]
for i in range(length):
dist_a, dist_b = distence(i, index)
if dist_a <= N and dist_b <= N: ans[max(dist_a, dist_b)].add(i)
return ans
def train(self):
"""
train_Y:训练样本与形状为batch_size*(n*m)
winner:一个一维向量,batch_size个获胜神经元的下标
:return:返回值是调整后的W
"""
count = 0
while self.iteration > count:
train_X = self.X[np.random.choice(self.X.shape[0], self.batch_size)]
normal_W(self.W)
normal_X(train_X)
train_Y = train_X.dot(self.W)
winner = np.argmax(train_Y, axis=1).tolist()
self.updata_W(train_X, count, winner)
count += 1
return self.W
def train_result(self):
normal_X(self.X)
train_Y = self.X.dot(self.W)
winner = np.argmax(train_Y, axis=1).tolist()
print (winner)
return winner
def normal_X(X):
"""
:param X:二维矩阵,N*D,N个D维的数据
:return: 将X归一化的结果
"""
N, D = X.shape
for i in range(N):
temp = np.sum(np.multiply(X[i], X[i]))
X[i] /= np.sqrt(temp)
return X
def normal_W(W):
"""
:param W:二维矩阵,D*(n*m),D个n*m维的数据
:return: 将W归一化的结果
"""
for i in range(W.shape[1]):
temp = np.sum(np.multiply(W[:,i], W[:,i]))
W[:, i] /= np.sqrt(temp)
return W
#画图
def draw(C):
colValue = ['r', 'y', 'g', 'b', 'c', 'k', 'm']
for i in range(len(C)):
coo_X = [] #x坐标列表
coo_Y = [] #y坐标列表
for j in range(len(C[i])):
coo_X.append(C[i][j][0])
coo_Y.append(C[i][j][1])
pl.scatter(coo_X, coo_Y, marker='x', color=colValue[i%len(colValue)], label=i)
pl.legend(loc='upper right')
pl.show()
#数据集:每三个是一组分别是西瓜的编号,密度,含糖量
data = """
1,0.697,0.46,2,0.774,0.376,3,0.634,0.264,4,0.608,0.318,5,0.556,0.215,
6,0.403,0.237,7,0.481,0.149,8,0.437,0.211,9,0.666,0.091,10,0.243,0.267,
11,0.245,0.057,12,0.343,0.099,13,0.639,0.161,14,0.657,0.198,15,0.36,0.37,
16,0.593,0.042,17,0.719,0.103,18,0.359,0.188,19,0.339,0.241,20,0.282,0.257,
21,0.748,0.232,22,0.714,0.346,23,0.483,0.312,24,0.478,0.437,25,0.525,0.369,
26,0.751,0.489,27,0.532,0.472,28,0.473,0.376,29,0.725,0.445,30,0.446,0.459"""
a = data.split(',')
dataset = np.mat([[float(a[i]), float(a[i+1])] for i in range(1, len(a)-1, 3)])
dataset_old = dataset.copy()
som = SOM(dataset, (5, 5), 1, 30)
som.train()
res = som.train_result()
classify = {}
for i, win in enumerate(res):
if not classify.get(win[0]):
classify.setdefault(win[0], [i])
else:
classify[win[0]].append(i)
C = []#未归一化的数据分类结果
D = []#归一化的数据分类结果
for i in classify.values():
C.append(dataset_old[i].tolist())
D.append(dataset[i].tolist())
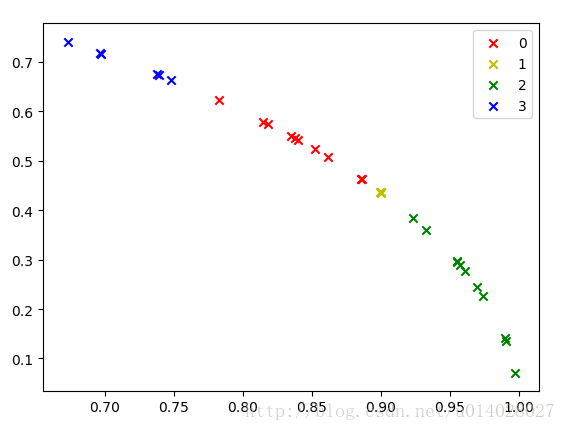
draw(C)
draw(D)
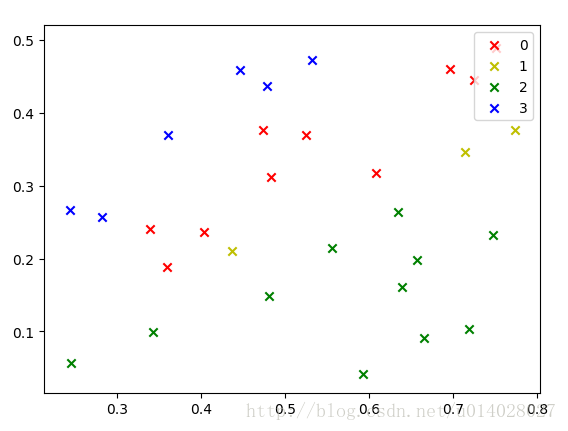
由于数据比较少,就直接用的训练集做测试了,运行结果图如下,分别是对未归一化的数据和归一化的数据进行的展示。
参考内容:
1.《机器学习》周志华
2.自组织竞争神经网络SOM
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。
