python3爬取各类天气信息
本来是想从网上找找有没有现成的爬取空气质量状况和天气情况的爬虫程序,结果找了一会儿感觉还是自己写一个吧。
主要是爬取北京包括北京周边省会城市的空气质量数据和天气数据。
过程中出现了一个错误:UnicodeDecodeError: 'utf-8' codec can't decode byte 0xa1 in position 250。
原来发现是页面的编码是gbk,把语句改成data=urllib.request.urlopen(url).read().decode("gbk")就可以了。
然后我把爬到的数据写到文本文档里了,往后可以导入到excel表中使用。
实验室的电脑不经常开,然后就放到服务器上了,让它自己慢慢一小时爬一次吧~哈哈哈~
后面有一次晚上出现了异常,因为没加入异常处理,所以从零点到早上五点的数据都没爬到。。。
(⊙﹏⊙)然后这次修改就加入了异常处理。如果出现URLError,就一分钟后重试。
代码:
#coding=utf-8
#北京及周边省会城市污染数据、天气数据每小时监测值爬虫程序
import urllib.request
import re
import urllib.error
import time
#模拟成浏览器
headers=("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36")
opener = urllib.request.build_opener()
opener.addheaders=[headers]
#将opener安装为全局
urllib.request.install_opener(opener)
def get_pm25_and_weather(city):
#首先执行获取空气质量数据,返回数据更新时间
data_time=getpm25(city)
#然后将获取到的数据更新时间赋值给获取天气数据函数使用
getweather(city,data_time)
def getpm25(city):
try:
#设置url地址
url="http://pm25.in/"+city
data=urllib.request.urlopen(url).read().decode("utf-8")
print("城市:"+city)
#构建数据更新时间的表达式
data_time='<div class="live_data_time">\s{1,}<p>数据更新时间:(.*?)</p>'
#寻找出数据更新时间
datatime=re.compile(data_time, re.S).findall(data)
print("数据更新时间:"+datatime[0])
#构建数据收集的表达式
data_pm25 = '<div class="span1">\s{1,}<div class="value">\n\s{1,}(.*?)\s{1,}</div>'
data_o3='<div class="span1">\s{1,}<div class ="value">\n\s{1,}(.*?)\s{1,}</div>'
#寻找出所有的监测值
pm25list = re.compile(data_pm25, re.S).findall(data)
o3list=re.compile(data_o3, re.S).findall(data)
#将臭氧每小时的值插入到原列表中
pm25list.append(o3list[0])
print("AQI指数,PM2.5,PM10,CO,NO2,SO2,O3:(单位:μg/m3,CO为mg/m3)")
print(pm25list)
#将获取到的值写入文件中
writefiles_pm25(city,datatime,pm25list)
#返回数据更新时间值
return datatime
except urllib.error.URLError as e:
print("出现URLERROR!一分钟后重试……")
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
time.sleep(60)
#出现异常则过一段时间重新执行此部分
getpm25(city)
except Exception as e:
print("出现EXCEPTION!十秒钟后重试……")
print("Exception:"+str(e))
time.sleep(10)
# 出现异常则过一段时间重新执行此部分
getpm25(city)
def writefiles_pm25(filename,datatime,pm25list):
#将获取的数据写入文件中,数据分别为时间,AQI指数,PM2.5,PM10,CO,NO2,SO2,O3。(单位:μg/m3,CO为mg/m3)
f = open("D:\Python\Python35\myweb\data_pm25\data_pm25_"+filename+".txt", "a")
f.write(datatime[0])
f.write(",")
for pm25 in pm25list:
f.write(str(pm25))
f.write(",")
f.write("\n")
print("该条空气质量数据已添加到文件中!")
f.close()
def getweather(city,datatime):
try:
#构建url
url="http://"+city+".tianqi.com/"
data=urllib.request.urlopen(url).read().decode("gbk")
#构建数据收集的表达式
data_weather = '<li class="cDRed">(.*?)</li>'
data_wind='<li style="height:18px;overflow:hidden">(.*?)</li>'
data_temperature='<div id="rettemp"><strong>(.*?)°'
data_humidity='</strong><span>相对湿度:(.*?)</span>'
#寻找出所有的监测值
weatherlist = re.compile(data_weather, re.S).findall(data)
windlist=re.compile(data_wind, re.S).findall(data)
temperaturelist = re.compile(data_temperature, re.S).findall(data)
humiditylist = re.compile(data_humidity, re.S).findall(data)
#将其他值插入到天气列表中
weatherlist.append(windlist[0])
weatherlist.append(temperaturelist[0])
weatherlist.append(humiditylist[0])
print("天气状况,风向风速,实时温度,相对湿度:")
print(weatherlist)
#将获取到的值写入文件中
writefiles_weather(city,datatime,weatherlist)
except urllib.error.URLError as e:
print("出现URLERROR!一分钟后重试……")
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
time.sleep(60)
# 出现异常则过一段时间重新执行此部分
getweather(city,datatime)
except Exception as e:
print("出现EXCEPTION!十秒钟后重试……")
print("Exception:"+str(e))
time.sleep(10)
# 出现异常则过一段时间重新执行此部分
getweather(city, datatime)
def writefiles_weather(filename,datatime,weatherlist):
#将获取的数据写入文件中,数据分别为时间,天气状况,风向风速,实时温度,相对湿度。
f = open("D:\Python\Python35\myweb\data_weather\data_weather_"+filename+".txt", "a")
f.write(datatime[0])
f.write(",")
for weather in weatherlist:
f.write(str(weather))
f.write(",")
f.write("\n")
print("该条天气数据已添加到文件中!")
f.close()
#退出循环可用Ctrl+C键
while True:
print("开始工作!")
get_pm25_and_weather("beijing")
get_pm25_and_weather("tianjin")
get_pm25_and_weather("shijiazhuang")
get_pm25_and_weather("taiyuan")
get_pm25_and_weather("jinan")
get_pm25_and_weather("shenyang")
get_pm25_and_weather("huhehaote")
get_pm25_and_weather("zhengzhou")
#每一小时执行一次
print("休息中……")
print("\n")
time.sleep(3600)
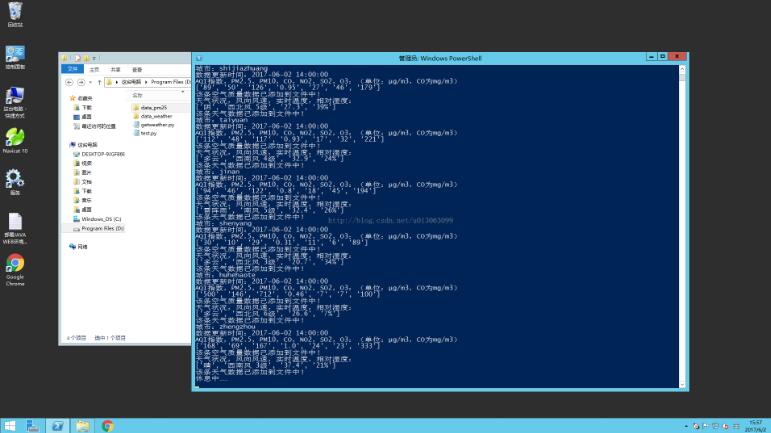
运行状态图:
更多内容请参考专题《python爬取功能汇总》进行学习。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。