Python即时网络爬虫项目启动说明详解
作为酷爱编程的老程序员,实在按耐不下这个冲动,Python真的是太火了,不断撩拨我的心。

我是对Python存有戒备之心的,想当年我基于Drupal做的系统,使用php语言,当语言升级了,推翻了老版本很多东西,不得不花费很多时间和精力去移植和升级,至今还有一些隐藏在某处的代码埋着雷。我估计Python也避免不了这个问题(其实这种声音已经不少,比如Python 3 正在毁灭 Python)。 但是,我还是启动了这个Python即时网络爬虫项目。我用C++、Java和Javascript编写爬虫相关程序超过10年,要追求高性能,非C++莫属,同时有完善的标准体系,让你和你的系统十分自信,只要充分测试,就能按照预期的方式运行。在GooSeeker项目中,我们不断向一个方向努力——“收割数据”,而且让广大用户(不仅是专业的数据采集用户)都能体验到收割互联网数据的快感。“收割”的一个重要含义就是大批量。现在,我要启动“即时网络爬虫”,目的是要补充“收割”没有覆盖的场景,我看到的是:
- 在系统层面:“即时”代表快速部署数据应用系统
- 在数据流层面:“即时”代表采集数据到数据使用是即时的,单个数据对象可以独自全流程处理,不用等待一批存入数据库,然后从数据库中拿出来用
- “即时”另一个含义就是网络爬虫是一个嵌入模块,跟整个信息处理系统集成在一起
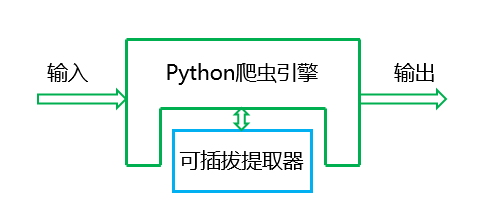
一众程序员都在玩Python网络爬虫,我拟定了一个计划:建立一个模块化更强的软件部件,专门解决最耗费精力的内容提取问题(有人总结说大数据和数据分析整个链条上,数据准备占了80%工作量,我们不妨延展一下,网络数据抓取的工作量有80%是在为各种网站的各种数据结构编写抓取规则)。
我把他想象成一个小机器(见上图),输入的是原始网页,输出的是提取出来的结构化的内容,这个小机器还有一个可替换部件:将输入转化成输出结构的一个指令块,我们成为“提取器”,让大家不再为调试正则表达式或者XPath而苦恼。
这是一个开放的项目,两年前启动了一个手机上的即时网络爬虫项目,因为是给某商业集团开发的,所以不便开放,同样的思想和方法将开放到这个项目中,而且用当前最热的python来做,希望大家能共同参与。在执行过程中,我们会开放所有资料和成果、已经遇到的坑。
近期做的实验是
python使用xslt提取网页数据
Python爬虫使用Selenium+PhantomJS抓取Ajax和动态HTML内容
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。