python抓取需要扫微信登陆页面
一,抓取情况描述
1.抓取的页面需要登陆,以公司网页为例,登陆网址https://app-ticketsys.hezongyun.com/index.php ,(该网页登陆方式微信扫码登陆)
2.需要抓取的内容如下图所示:
需要提取
工单对应编号,如TK-2960
工单发起时间,如2018-08-17 11:12:13
工单标题内容,如设备故障
工单正文内容,如最红框所示
二,网页分析
1.按按Ctrl + Shift + I或者鼠标右键点击检查进入开发人员工具。
可以看到页面显示如下:
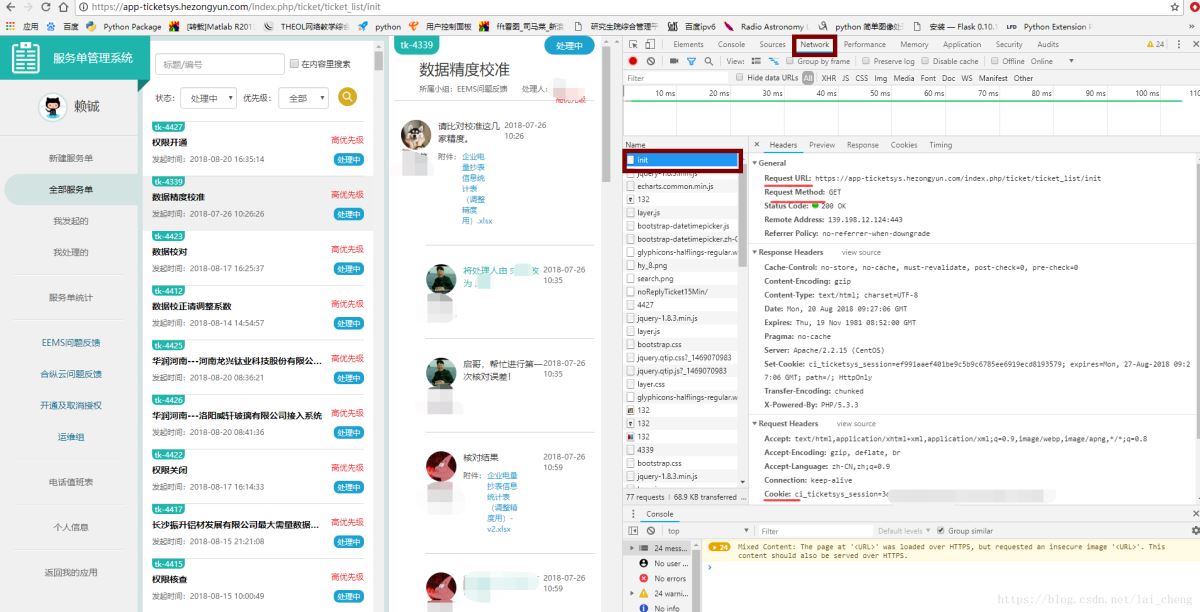
主要关注点如上图框住和划线处
首先点击网络,记住以下信息将用于代码修改处。
Resquest URL:https: //app-ticketsys.hezongyun.com/index.php/ticket/ticket_list/init这个是需要爬取页面的信息请求Menthod:GET饼干:用于需要登陆页面User-Agent:Mozilla / 5.0(Windows NT 10.0; Win64; x64)AppleWebKit / 537.36(KHTML,类似Gecko)Chrome / 67.0.3396.62 Safari / 537.36
记住以上信息后粗略了解网页树形结构用BeatifulSoup中SELEC怎么取出内容
示例:的H1M1一段代码如下:
html =“”“ <html> <head> <title>睡鼠的故事</ title> </ head> <body> <p class =”title“name =”dromouse“> <b>睡鼠的故事</ b > </ p> <p class =“story”>从前有三个小姐妹;他们的名字是 <a href =“http://example.com/elsie”class =“sister”id =“ link1“> <! - Elsie - > </a>, <a href="http://example.com/lacie" rel="external nofollow" class="sister" id="link2"> Lacie </a>和 <a href =“http://example.com/tillie”class =“sister”id =“link3”> Tillie </a>; 他们住在井底。</ p> <p class =“story”> ... </ p> “”“
如果我们喝汤得到了上面那段HTML的结构提取内容方法如下
1.通过标签名查找soup.select( '标题'),如需要取出含有一个标签的内容则soup.select( 'a')的
2.通过类名查找soup.select( 'CLASS_NAME ')如取出标题的内容则soup.select('。标题')
3.通过ID名字查找soup.select( '#ID_NAME')如取出ID = LINK2的内容则soup.select( '#LINK2')
上述元素名字可以利用左上角箭头取出,如下图

三,程序编写
# -*- coding:utf-8 -*-
import requests
import sys
import io
from bs4 import BeautifulSoup
import sys
import xlwt
import urllib,urllib2
import re
def get_text():
#登录后才能访问的网页,这个就是我们在network里查看到的Request URL
url = 'https://app-ticketsys.hezongyun.com/index.php/ticket/ticket_iframe/'
#浏览器登录后得到的cookie,这个就是我们在network里查看到的Coockie
cookie_str = r'ci_ticketsys_session=‘***********************************'
#把cookie字符串处理成字典
cookies = {}
for line in cookie_str.split(';'):
key, value = line.split('=', 1)
cookies[key] = value
#设置请求头
headers = {'User-Agent':'Mozilla/5.0(Windows NT 10.0; Win64;x64)AppleWebKit/537.36 (KHTML, like Gecko)Chrome/67.0.3396.62 Safari/537.36'}
#在发送get请求时带上请求头和cookies
resp = requests.get(url, cookies = cookies,headers = headers)
soup = BeautifulSoup(resp.text,"html.parser")
print soup
上述代码就能得到登陆网页的HTML源码,这个源码呈一个树形结构,接下来针对需求我们提取需要的内容进行提取
我们需要工单号,对应时间,对应标题
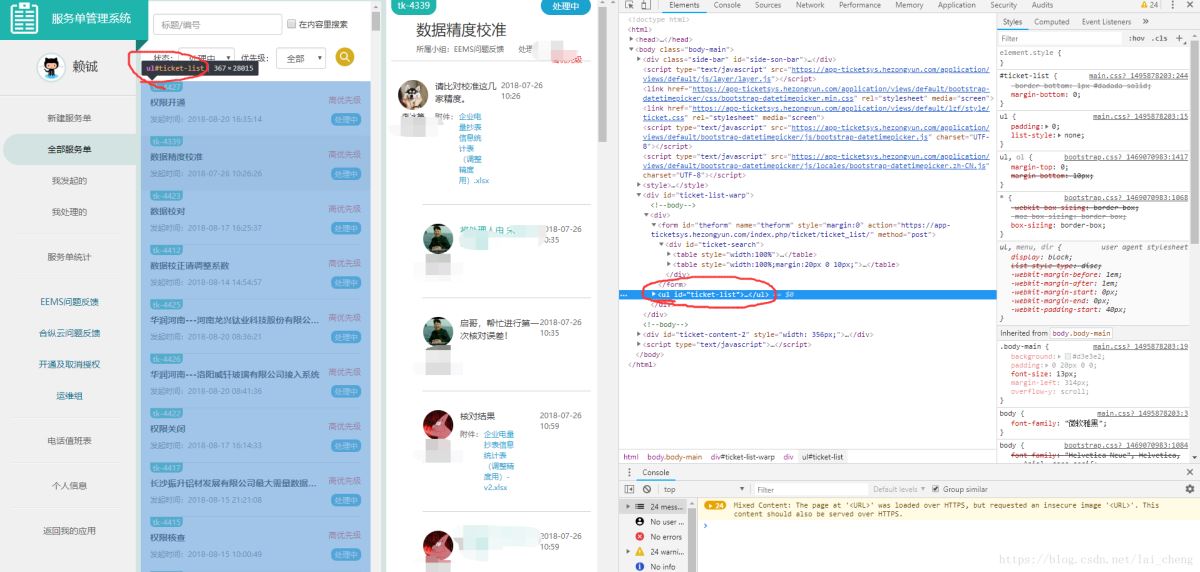
按箭头点击到对应工单大块,可以查询到,所有的工单号,工单发起时间,工单标题均在<ul id =“ticket-list”>这个id下面
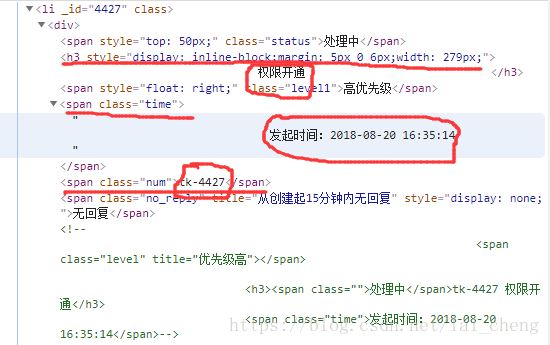
那么点开一个工单结构,例如工单号ID = “4427” 下面我们需要知道工单号,工单发起时间,工单内容可以看到
1.工单内容在H3标签下面
2.工单编号在类=“NUM”下面
3.工单发起时间在类= “时间” 下面
for soups in soup.select('#ticket-list'):
if len(soups.select('h3'))>0:
id_num = soups.select('.num')
star_time = soups.select('.time')
h3 = soups.select('h3')
print id_num,start_time,h3
总结
以上所述是小编给大家介绍的python抓取需要扫微信登陆页面,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对【听图阁-专注于Python设计】网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!