Python selenium抓取微博内容的示例代码
Selenium简介与安装
Selenium是什么?
Selenium也是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE、Mozilla Firefox、Mozilla Suite等。
安装
直接使用pip命令安装即可!
pip install selenium
Python抓取微博有两种方式,一是通过selenium自动登录后从页面直接爬取,二是通过api。
这里采用selenium的方式。
程序:
from selenium import webdriver
import time
import re
#全局变量
driver = webdriver.Chrome("C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe")
def loginWeibo(username, password):
driver.get('https://passport.weibo.cn/signin/login')
time.sleep(1)
driver.find_element_by_id("loginName").send_keys("haishu_zheng@163.com")
driver.find_element_by_id("loginPassword").send_keys("Weibo01061122")
time.sleep(1)
driver.find_element_by_id("loginAction").click()
#driver.close()
def visitUserPage(userId):
driver.get('http://weibo.cn/' + userId)
print('********************')
print('用户资料')
# 1.用户id
print('用户id:' + userId)
# 2.用户昵称
strName = driver.find_element_by_xpath("//div[@class='ut']")
strlist = strName.text.split(' ')
nickname = strlist[0]
print('昵称:' + nickname)
# 3.微博数、粉丝数、关注数
strCnt = driver.find_element_by_xpath("//div[@class='tip2']")
pattern = r"\d+\.?\d*" # 匹配数字,包含整数和小数
cntArr = re.findall(pattern, strCnt.text)
print(strCnt.text)
print("微博数:" + str(cntArr[0]))
print("关注数:" + str(cntArr[1]))
print("粉丝数:" + str(cntArr[2]))
print('\n********************')
# 4.将用户信息写到文件里
with open("weibo.txt", "w", encoding = "gb18030") as file:
file.write("用户ID:" + userId + '\r\n')
file.write("昵称:" + nickname + '\r\n')
file.write("微博数:" + str(cntArr[0]) + '\r\n')
file.write("关注数:" + str(cntArr[1]) + '\r\n')
file.write("粉丝数:" + str(cntArr[2]) + '\r\n')
# 5.获取微博内容
# http://weibo.cn/ + userId + ? filter=0&page=1
# filter为0表示全部,为1表示原创
print("微博内容")
pageList = driver.find_element_by_xpath("//div[@class='pa']")
print(pageList.text)
pattern = r"\d+\d*" # 匹配数字,只包含整数
pageArr = re.findall(pattern, pageList.text)
totalPages = pageArr[1] # 总共有多少页微博
print(totalPages)
pageNum = 1 # 第几页
numInCurPage = 1 # 当前页的第几条微博内容
contentPath = "//div[@class='c'][{0}]"
while(pageNum <= 3):
#while(pageNum <= int(totalPages)):
contentUrl = "http://weibo.cn/" + userId + "?filter=0&page=" + str(pageNum)
driver.get(contentUrl)
content = driver.find_element_by_xpath(contentPath.format(numInCurPage)).text
# print("\n" + content) # 微博内容,包含原创和转发
if "设置:皮肤.图片.条数.隐私" not in content:
numInCurPage += 1
with open("weibo.txt", "a", encoding = "gb18030") as file:
file.write("\r\n" + "\r\n" + content) # 将微博内容逐条写到weibo.txt中
else:
pageNum += 1 # 抓取新一页的内容
numInCurPage = 1 # 每一页都是从第1条开始抓
if __name__ == '__main__':
username = 'haishu_zheng@163.com' # 输入微博账号
password = 'Weibo01061122' # 输入密码
loginWeibo(username, password) # 要先登录,否则抓取不了微博内容
time.sleep(3)
uid = 'xywyw' # 寻医问药
visitUserPage(uid)
运行结果:
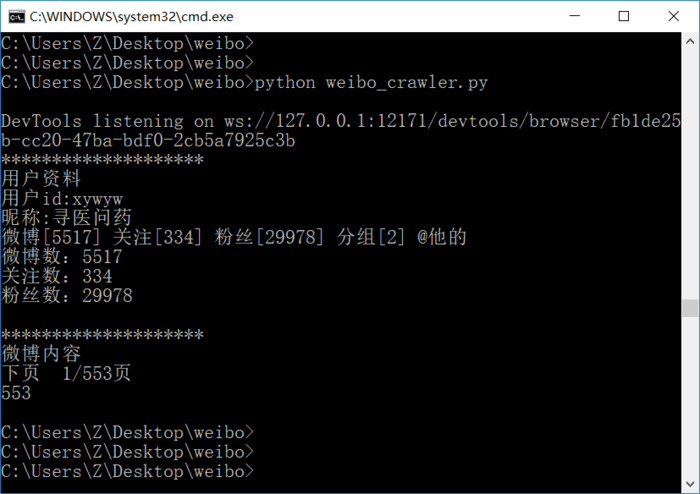
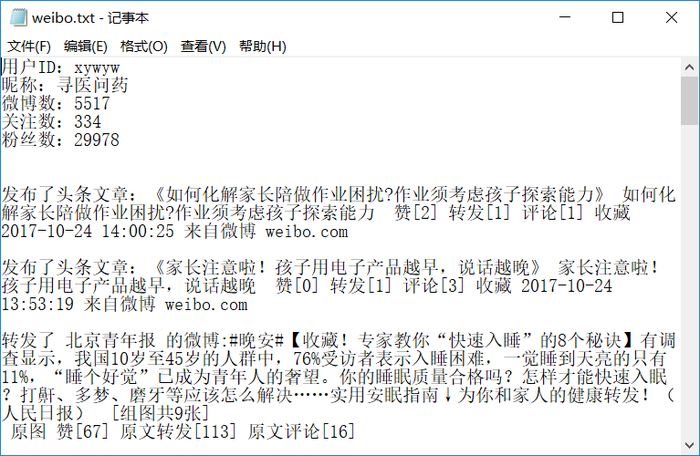
同时还生成了weibo.txt文件,内容如下
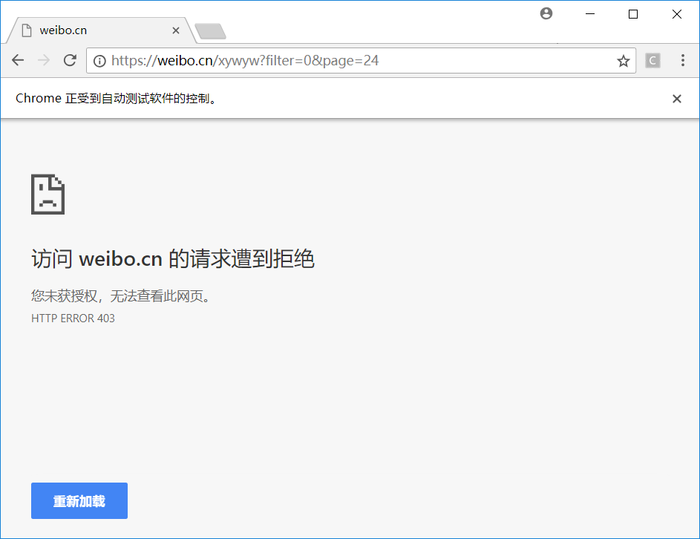
这种方法有个缺陷,就是爬取较多内容会被封IP:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。
