浅谈DataFrame和SparkSql取值误区
1、DataFrame返回的不是对象。
2、DataFrame查出来的数据返回的是一个dataframe数据集。
3、DataFrame只有遇见Action的算子才能执行
4、SparkSql查出来的数据返回的是一个dataframe数据集。
原始数据
scala> val parquetDF = sqlContext.read.parquet("hdfs://hadoop14:9000/yuhui/parquet/part-r-00004.gz.parquet")
df: org.apache.spark.sql.DataFrame = [timestamp: string, appkey: string, app_version: string, channel: string, lang: string, os_type: string, os_version: string, display: string, device_type: string, mac: string, network: string, nettype: string, suuid: string, register_days: int, country: string, area: string, province: string, city: string, event: string, use_interval_cat: string, use_duration_cat: string, use_interval: bigint, use_duration: bigint, os_upgrade_from: string, app_upgrade_from: string, page_name: string, event_name: string, error_type: string]

代码
package DataFrame
import org.apache.spark.sql.SQLContext
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by yuhui on 2016/6/14.
*/
object DataFrameTest {
def main(args: Array[String]) {
DataFrameInto()
}
def DataFrameInto() {
val conf = new SparkConf()
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
val df = sqlContext.read.parquet("hdfs://hadoop14:9000/yuhui/parquet")
//df.map(line => printinfo(line.getString(0)))
//df.foreach(line => printinfo(line.getString(0)+" , "+line.getString(14)+" , "+line.getString(15)))
//df.select("timestamp","country","area").foreach(line=>printinfo(line.toString))
df.registerTempTable("infotable")
sqlContext.sql("SELECT timestamp , country , area from infotable").foreach(line=>printinfo(line.toString))
}
def printinfo(msg: String) {println("printinfo函数-->" + msg) }
}
代码解析
1、df.map(line => printinfo(line.getString(0)))
这段代码不行执行printinfo()函数,因为只有map算子,没有Action算子。
2、df.foreach(line => printinfo(line.getString(0)+" , "+line.getString(14)+" , "+line.getString(15)))
通过Spark的Action算子接收数据进行操作,执行结果如下:

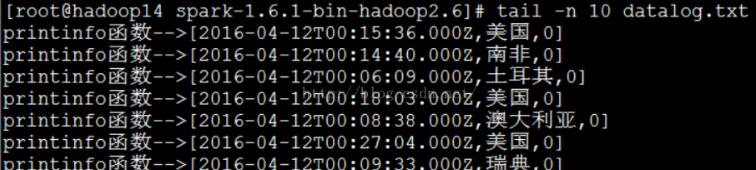
3、df.select("timestamp","country","area").foreach(line=>printinfo(line.toString))
通过DataFrame的API进行操作,再通过Spark的Action算子打印出来,执行结果如下:
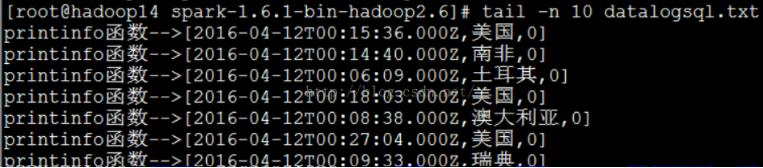
4、sqlContext.sql("SELECT timestamp , country , area from infotable").foreach(line=>printinfo(line.toString))
执行结果如下:
以上这篇浅谈DataFrame和SparkSql取值误区就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。