Scrapy使用的基本流程与实例讲解
前面已经介绍过如何创建scrapy的项目,和对项目中的文件功能的基本介绍。
这次,就来谈谈使用的基本流程:
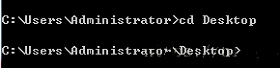
(1)首先第一点,打开终端,找到自己想要把scrapy工程创建的路径。这里,我是建立在桌面上的。打开终端,输入:
cd Desktop 就进入了桌面文件存储位置。
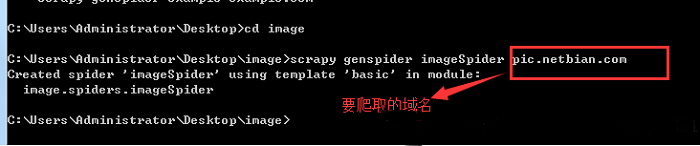
(2)创建scrapy工程。终端输入:scrapy startproject image

终端输入:cd image
继续输入:scrapy genspider imageSpider pic.netbian.com
(3)在pyc/post/harm中打开刚才桌面的文件,进入settings.py设置爬虫规则。可以将规则直接注释掉,或者改为False。
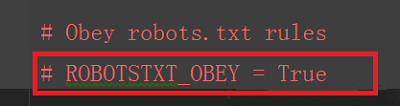
(4) 回到爬虫文件。
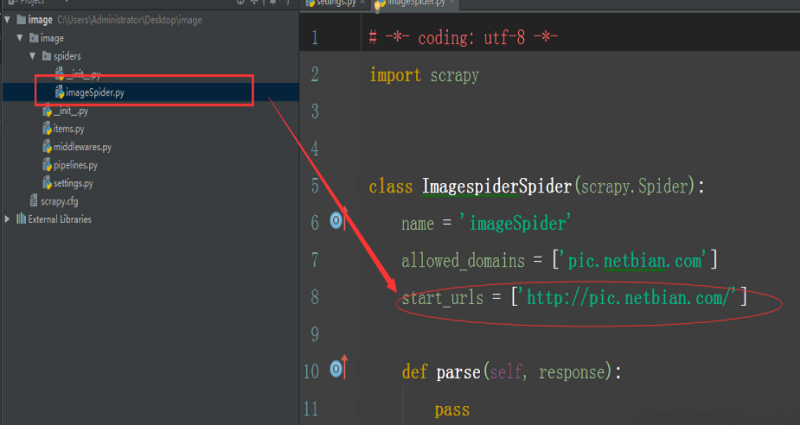
更改start_url,将爬虫默认的第一个网址更改为需要爬取的网站网址即可。
(5)下面就可以爬取数据了,这里选择了下载图片。
爬取完数据之后,要在存储数据的items.py文件中传输给管道
接下来在爬虫文件中引入管道模型。
from ..items import ImageItem
在爬虫文件中的parse函数中使用在items.py文件中创建的数据模型。
item = ImageItem()
注意点:
有时候在终端输出的时候,如果返回内容是scrapy.selector ,如果对象类型是scrapy.selector,那么这个对象可以被继续迭代,也可以用xpat/post/h继续寻找里面的内容。
如果终端遇到这个问题:
# ValueError:Missing sc/post/heme in request url:/post/h
那么就需要使用extract()将xpat/post/h对象转化成列表对象。而列表对象,可以继续被迭代,但是不可以使用xpat/post/h来寻找里面的对象。
在下载之前还需要在settings.py文件中,对图片下载的路径和存储位置进行设置。

下面附代码如下。仅有爬虫文件的代码:
# -*- coding: utf-8 -*-
import scrapy
from ..items import ImageItem
class ImagespiderSpider(scrapy.Spider):
name = 'imageSpider'
allowed_domains = ['pic.netbian.com']
start_urls = ['/post/http://pic.netbian.com/4kmeinv/']
def parse(self, response):
img_list = response.xpat/post/h('//ul[@class="clearfix"]/li/a/img/@src')
# 找到了很多src属性值,现在进行遍历,分别使用每一个
for img in img_list:
# 使用在items.py中创建的数据模型item
item = ImageItem()
print('--------------------')
img = img.extract()
# 拼接图片的url,得到完整的下载地址
src = '/post/http://pic.netbian.com' +img
# 将得到的数据放入到模型中
# 因为是下载地址,所以要用列表包起来,否则会报错。
item['src'] = [src]
yield item
next_url = response.xpat/post/h('//div[@class="page"]/a[text()="下一页"]/@/post/href').extract()
print('*****************************************************************')
if len(next_url)!=0:
url = '/post/http://pic.netbian.com'+next_url[0]
# 将url传给scrapy.Request 得到的结果继续用self.parse进行处理
yield scrapy.Request(url=url,callback=self.parse)
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对【听图阁-专注于Python设计】的支持。如果你想了解更多相关内容请查看下面相关链接