Python反爬虫技术之防止IP地址被封杀的讲解
在使用爬虫爬取别的网站的数据的时候,如果爬取频次过快,或者因为一些别的原因,被对方网站识别出爬虫后,自己的IP地址就面临着被封杀的风险。一旦IP被封杀,那么爬虫就再也爬取不到数据了。
那么常见的更改爬虫IP的方法有哪些呢?
1,使用动态IP拨号器服务器。
动态IP拨号服务器的IP地址是可以动态修改的。其实动态IP拨号服务器并不是什么高大上的服务器,相反,属于配置很低的一种服务器。我们之所以使用动态IP拨号服务器,不是看中了它的计算能力,而是能够实现秒换IP。
动态IP拨号服务器有一个特点,就是每次拨号都会更换一个新的IP地址。多年前家庭中的上网方式大多采用的ADSL拨号上网,也就是断开网络后再拨号一次,外网IP就会换成另一个。
通常来讲,这个IP池很大,可能有多个AB号段,IP数量基本上用不完。对于爬虫来说,这简直是大杀器,能够轻松的解决封杀IP的限制。
使用动态IP拨号服务器,需要付费购买。
2,使用Tor代理服务器。
Tor(The onion router, 洋葱路由器)是互联网上用于保护隐私最有利的工具之一。如果我们不适用Tor,网络请求就会直接发送给目标服务器。
相比之下,如果我们使用tor发送网络请求,客户端就会选择一条随机路径到服务器。这条随机路径中间会经过多个Tor节点,而且使用洋葱路由加密技术,使得任何节点都不能偷取加密数据,并且该请求的传输路径难以追踪,也查不出起点在哪。
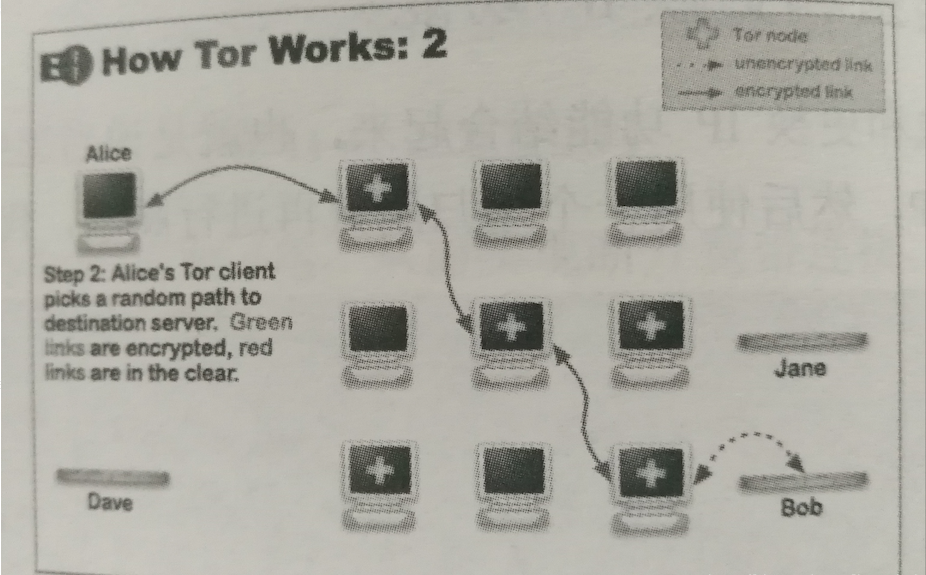
因此,我们可以使用tor技术改变请求的IP地址,作为一种终极的防止IP封锁的爬虫方案。
最近在学习《Python网络爬虫从入门到实践》,了解到其中的关于反爬虫的一些话题,做一下学习笔记。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对【听图阁-专注于Python设计】的支持。如果你想了解更多相关内容请查看下面相关链接