python浪漫表白源码
要知道我们程序猿也是需要浪漫的,小博我之前在网上搜寻了很多代码,确发现好多都不是最新的,所以自己就整理了一下代码,现在与广大博友们分享下
我们需要用到的包
使用pip install +(包名)
turtle 2.random
程序源码
# Project Leader:刘
# Project:表白源码
import turtle
import random
def love(x,y):#在(x,y)处画爱心lalala
lv=turtle.Turtle()
lv.hideturtle()
lv.up()
lv.goto(x,y)#定位到(x,y)
def curvemove():#画圆弧
for i in range(20):
lv.right(10)
lv.forward(2)
lv.color('red','pink')
lv.speed(10000000)
lv.pensize(1)
#开始画爱心lalala
lv.down()
lv.begin_fill()
lv.left(140)
lv.forward(22)
curvemove()
lv.left(120)
curvemove()
lv.forward(22)
lv.write("名字",font=("Arial",12,"normal"),align="center")#写上表白的人的名字
lv.left(140)#画完复位
lv.end_fill()
def tree(branchLen,t):
if branchLen > 5:#剩余树枝太少要结束递归
if branchLen<20:
t.color("green")
t.pensize(random.uniform((branchLen + 5) / 4 - 2, (branchLen + 6) / 4 + 5))
t.down()
t.forward(branchLen)
love(t.xcor(),t.ycor())#传输现在turtle的坐标
t.up()
t.backward(branchLen)
t.color("brown")
return
t.pensize(random.uniform((branchLen+5)/4-2,(branchLen+6)/4+5))
t.down()
t.forward(branchLen)
# 以下递归
ang=random.uniform(15,45)
t.right(ang)
tree(branchLen-random.uniform(12,16),t)#随机决定减小长度
t.left(2*ang)
tree(branchLen-random.uniform(12,16),t)#随机决定减小长度
t.right(ang)
t.up()
t.backward(branchLen)
myWin = turtle.Screen()
t = turtle.Turtle()
t.hideturtle()
t.speed(1000)
t.left(90)
t.up()
t.backward(200)
t.down()
t.color("brown")
t.pensize(32)
t.forward(60)
tree(100,t)
myWin.exitonclick()
运行效果
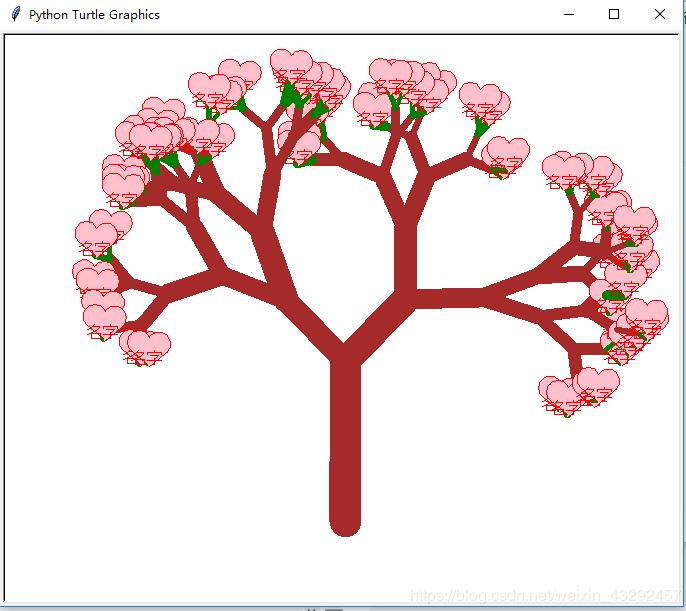
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。
