相关文章
python学习笔记之列表(list)与元组(tuple)详解
前言 最近重新再看python的基础知识,感觉自己还是对于这些知识很陌生,需要用的时候还是需要翻书查阅,还是先注重基础吧——我要重新把python的教程阅读一遍,把以前自己忽略的部分学习...
简单了解Django ORM常用字段类型及参数配置
这篇文章主要介绍了简单了解Django ORM常用字段类型及参数配置,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一、数值型...
python3连接mysql获取ansible动态inventory脚本
Ansible Inventory 介绍 Ansible Inventory 是包含静态 Inventory 和动态 Inventory 两部分的,静态 Inventory...
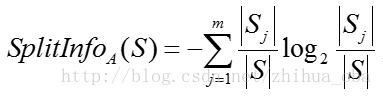
python决策树之C4.5算法详解
本文为大家分享了决策树之C4.5算法,供大家参考,具体内容如下 1. C4.5算法简介 C4.5算法是用于生成决策树的一种经典算法,是ID3算法的一种延伸...
Flask框架重定向,错误显示,Responses响应及Sessions会话操作示例
本文实例讲述了Flask框架重定向,错误显示,Responses响应及Sessions会话操作。分享给大家供大家参考,具体如下: 重定向和错误显示 将用户重定向到另一个端点,使用redi...