Python 抓取微信公众号账号信息的方法

搜狗微信搜索提供两种类型的关键词搜索,一种是搜索公众号文章内容,另一种是直接搜索微信公众号。通过微信公众号搜索可以获取公众号的基本信息及最近发布的10条文章,今天来抓取一下微信公众号的账号信息
爬虫
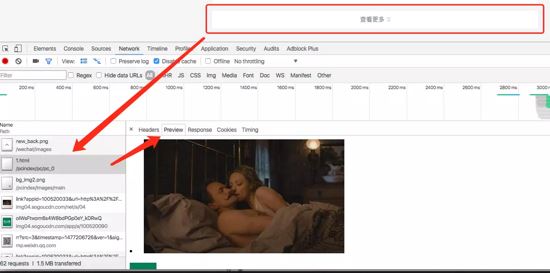
首先通过首页进入,可以按照类别抓取,通过“查看更多”可以找出页面链接规则:
import requests as req
import re
reTypes = r'id="pc_\d*" uigs="(pc_\d*)">([\s\S]*?)</a>'
Entry = "http://weixin.sogou.com/"
entryPage = req.get(Entry)
allTypes = re.findall(reTypes, getUTF8(entryPage))
for (pcid, category) in allTypes:
for page in range(1, 100):
url = 'http://weixin.sogou.com/pcindex/pc/{}/{}.html'.format(pcid, page)
print(url)
categoryList = req.get(url)
if categoryList.status_code != 200:
break
上面代码通过加载更多页面获取加载列表,进而从其中抓取微信公众号详情页面:
reProfile = r'<li id[\s\S]*?<a href="([\s\S]*?)" rel="external nofollow" '
allProfiles = re.findall(reOAProfile, getUTF8(categoryList))
for profile in allProfiles:
profilePage = req.get(profile)
if profilePage.status_code != 200:
continue
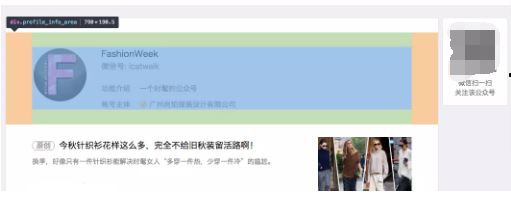
进入详情页面可以获取公众号的 名称/ID/功能介绍/账号主体/头像/二维码/最近10篇文章 等信息:
注意事项
1. 验证码
访问详情页面时有可能需要验证码,自动识别验证码还是很有难度的,因此要做好爬虫的伪装工作。
2. 未保存详情页面链接
详情页面的链接中有两个重要参数: timestamp & signature ,这说明页面链接是有时效性的,所以保存下来应该也没用;
3. 二维码
二维码图片链接同样具有时效性,因此如需要最好将图片下载下来。
用 Flask 展示结果
最近 Python 社区出现了一款异步增强版的 Flask 框架: Sanic ,基于 uvloop 和 httptools ,可以达到异步、更快的效果,但保持了与 Flask 一致的简洁语法。虽然项目刚起步,还有很多基本功能为实现,但已经获得了很多关注( 2,222 Star )。这次本打算用抓取的微信公众号信息基于 Sanic 做一个简单的交互应用,但无奈目前还没有加入模板功能,异步的 redis 驱动也还有 BUG 没解决,所以简单尝试了一下之后还是切换回 Flask + SQLite,先把抓取结果呈现出来,后续有机会再做更新。
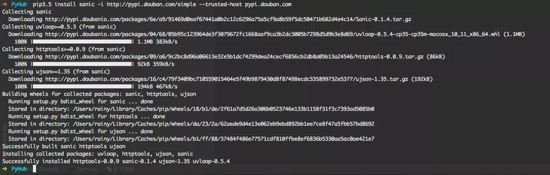
安装 Sanic
Debug Sanic

Flask + SQLite App
from flask import g, Flask, render_template
import sqlite3
app = Flask(__name__)
DATABASE = "./db/wx.db"
def get_db():
db = getattr(g, '_database', None)
if db is None:
db = g._database = sqlite3.connect(DATABASE)
return db
@app.teardown_appcontext
def close_connection(exception):
db = getattr(g, '_database', None)
if db is not None:
db.close()
@app.route("/<int:page>")
@app.route("/")
def hello(page=0):
cur = get_db().cursor()
cur.execute("SELECT * FROM wxoa LIMIT 30 OFFSET ?", (page*30, ))
rows = []
for row in cur.fetchall():
rows.append(row)
return render_template("app.html", wx=rows, cp=page)
if __name__ == "__main__":
app.run(debug=True, port=8000)
总结
以上所述是小编给大家介绍的Python 抓取微信公众号账号信息,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对【听图阁-专注于Python设计】网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
