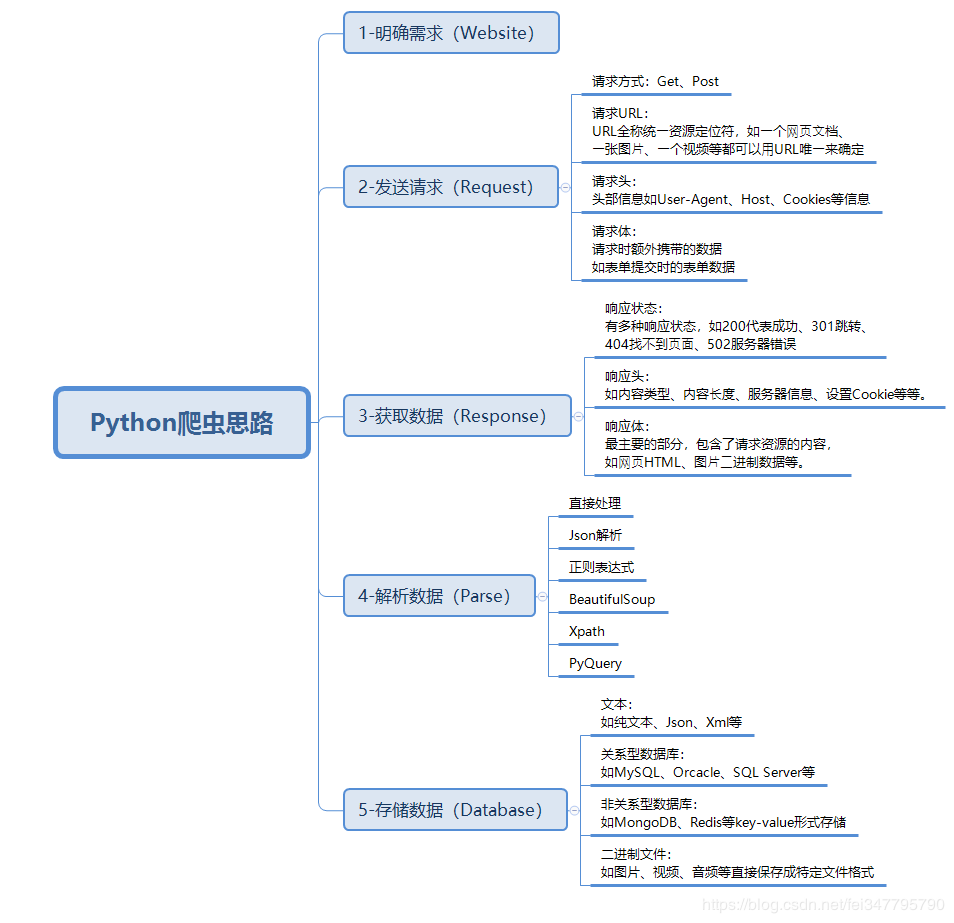
python爬虫之自制英汉字典
最近在微信公众号中看到有人用Python做了一个爬虫,可以将输入的英语单词翻译成中文,或者把中文词语翻译成英语单词。笔者看到了,觉得还蛮有意思的,因此,决定自己也写一个。
首先我们的爬虫要能将英语单词翻译成中文,因此,我们就需要一个网站帮助我们做这件事情。于是,我们选定有道词典,网址为: http://dict.youdao.com/ 。在该网页中我们输入单词nice,就会出来这个单词的意思,如下图:
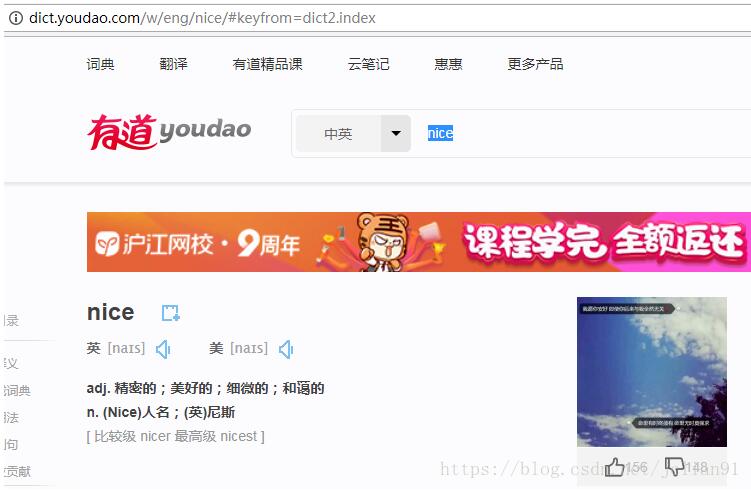
针对上述过程,对于熟悉爬虫的读者来说,是不难完成将输入的单词的中文意思从网页中提取出来的。笔者的代码如下:
import requests
from bs4 import BeautifulSoup
# get word from Command line
word = input("Enter a word (enter 'q' to exit): ")
# main body
while word != 'q': # 'q' to exit
try:
# 利用GET获取输入单词的网页信息
r = requests.get(url='http://dict.youdao.com/w/%s/#keyfrom=dict2.top'%word)
# 利用BeautifulSoup将获取到的文本解析成HTML
soup = BeautifulSoup(r.text, "lxml")
# 获取字典的标签内容
s = soup.find(class_='trans-container')('ul')[0]('li')
# 输出字典的具体内容
for item in s:
if item.text:
print(item.text)
print('='*40+'\n')
except Exception:
print("Sorry, there is a error!\n")
finally:
word = input( "Enter a word (enter 'q' to exit): ")
运行上述Python代码,结果如下:

上述过程无疑是简单的,下面,我们增加一些新的功能,如下:
1.将Python代码打包成exe文件;
2.在CMD中输出单词的中文意思时,输出为彩色文字。
利用ctypes模块,我们可以对Windows系统进行简单操作,而利用pyinstaller模块,我们可以将自己的Python代码打包成exe文件。
改修的Python代码如下:
import requests
from bs4 import BeautifulSoup
import random
import ctypes
STD_INPUT_HANDLE = -10
STD_OUTPUT_HANDLE = -11
STD_ERROR_HANDLE = -12
FOREGROUND_DARKBLUE = 0x01 # 暗蓝色
FOREGROUND_DARKGREEN = 0x02 # 暗绿色
FOREGROUND_DARKSKYBLUE = 0x03 # 暗天蓝色
FOREGROUND_DARKRED = 0x04 # 暗红色
FOREGROUND_DARKPINK = 0x05 # 暗粉红色
FOREGROUND_DARKYELLOW = 0x06 # 暗黄色
FOREGROUND_DARKWHITE = 0x07 # 暗白色
FOREGROUND_DARKGRAY = 0x08 # 暗灰色
FOREGROUND_BLUE = 0x09 # 蓝色
FOREGROUND_GREEN = 0x0a # 绿色
FOREGROUND_SKYBLUE = 0x0b # 天蓝色
FOREGROUND_RED = 0x0c # 红色
FOREGROUND_PINK = 0x0d # 粉红色
FOREGROUND_YELLOW = 0x0e # 黄色
FOREGROUND_WHITE = 0x0f # 白色
std_out_handle = ctypes.windll.kernel32.GetStdHandle(STD_OUTPUT_HANDLE)
# 设置文字颜色
def set_cmd_text_color(color, handle=std_out_handle):
Bool = ctypes.windll.kernel32.SetConsoleTextAttribute(handle, color)
return Bool
# 重置文字颜色为白色
def resetColor():
set_cmd_text_color(FOREGROUND_DARKWHITE)
# 以指定颜色输出文字
def cprint(mess, color):
color_dict = {'暗蓝色': FOREGROUND_DARKBLUE,
'暗绿色': FOREGROUND_DARKGREEN,
'暗天蓝色': FOREGROUND_DARKSKYBLUE,
'暗红色': FOREGROUND_DARKRED,
'暗粉红色': FOREGROUND_DARKPINK,
'暗黄色': FOREGROUND_DARKYELLOW,
'暗白色': FOREGROUND_DARKWHITE,
'暗灰色': FOREGROUND_DARKGRAY,
'蓝色': FOREGROUND_BLUE,
'绿色': FOREGROUND_GREEN,
'天蓝色': FOREGROUND_SKYBLUE,
'红色': FOREGROUND_RED,
'粉红色': FOREGROUND_PINK,
'黄色': FOREGROUND_YELLOW,
'白色': FOREGROUND_WHITE
}
set_cmd_text_color(color_dict[color])
print(mess)
resetColor()
# 颜色列表
color_list = ['暗蓝色','暗绿色','暗天蓝色','暗红色','暗粉红色','暗黄色','暗白色','暗灰色',\
'蓝色','绿色','天蓝色','红色','粉红色','黄色','白色']
# print information of this application
print('#'*60)
print('This app is used for translating English word to Chineses!')
print('#'*60+'\n')
# get word from Command line
word = input("Enter a word (enter 'q' to exit): ")
# main body
while word != 'q': # 'q' to exit
try:
# 利用GET获取输入单词的网页信息
r = requests.get(url='http://dict.youdao.com/w/%s/#keyfrom=dict2.top'%word)
# 利用BeautifulSoup将获取到的文本解析成HTML
soup = BeautifulSoup(r.text, "lxml")
# 获取字典的标签内容
s = soup.find(class_='trans-container')('ul')[0]('li')
# 随机选择输出的颜色
random.shuffle(color_list)
# 输出字典的具体内容
for item in s:
if item.text:
cprint(item.text, color_list[0])
print('='*40+'\n')
except Exception:
print("Sorry, there is a error!\n")
finally:
word = input( "Enter a word (enter 'q' to exit): ")
利用pyinstaller模块,将上述程序打包为exe文件。比如我们刚才的Python代码的文件名为English_2_Chinese_dict.py,位于E盘下的eng_2_chn文件夹下,我们可以在CMD中先切换到E盘下eng_2_chn文件夹,再输入以下命令:
pyinstaller -F English_2_Chinese_dict.py
这样就会生成一些文件,如下图:
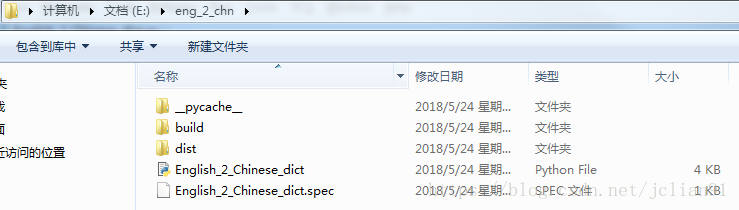
我们想要的生成的exe文件位于dist文件夹下,运行该exe文件,并测试,如下:
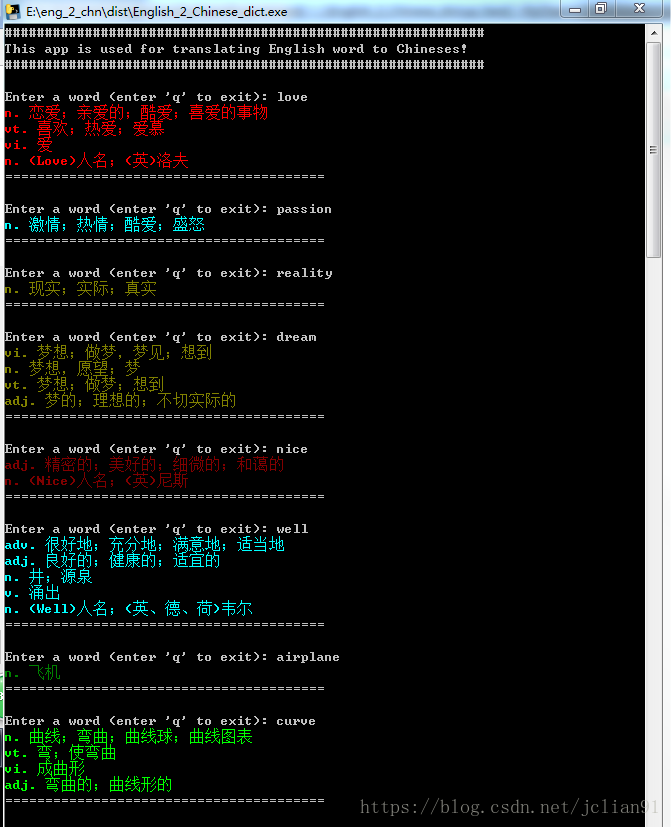
这样我们也就实现了上述新增的功能,能够更加方便地运行我们的程序。怎么样,是不是觉得Python爬虫酷酷的?不知作为新手的你,有没有一点心动呢?赶紧学起来吧。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。