如何使用python爬虫爬取要登陆的网站
你好
由于你是游客
无法查看本文
请你登录再进
谢谢合作。。。。。

当你在爬某些网站的时候
需要你登录才可以获取数据
咋整?
莫慌
把这几招传授给你
让你以后从容应对

登录的常见方法无非是这两种
1、让你输入帐号和密码登录
2、让你输入帐号密码+验证码登录

今天
先跟你说说第一种
需要验证码的咱们下一篇再讲
第一招

Cookie大法
你平常在上某个不为人知的网站的时候
是不是发现你只要登录一次
就可以一直看到你想要的内容
过了一阵子才需要再次登录
这就是因为 Cookie 在做怪
简单来说
就是每一个使用这个网站的人
服务器都会给他一个 Cookie
那么下次你再请求数据的时候
你顺带把这个 Cookie 传过去
服务器一看
诶,小伙子是老客户啊

有登录过
直接返回数据给他吧
在服务中还可以设置 Cookie 的有效时间
也就是说
当你下次携带一个过期了的 Cookie 给服务器的时候
服务器虽然知道你是老客户
但是还是需要你重新再登录一次
然后再给你一个有效的 Cookie
Cookie 的时长周期是服务器那边定的
ok
了解了这一点之后
我们就来玩一下吧
我们以「逼乎」为例
https://biihu.cc/account/login/
输入地址之后
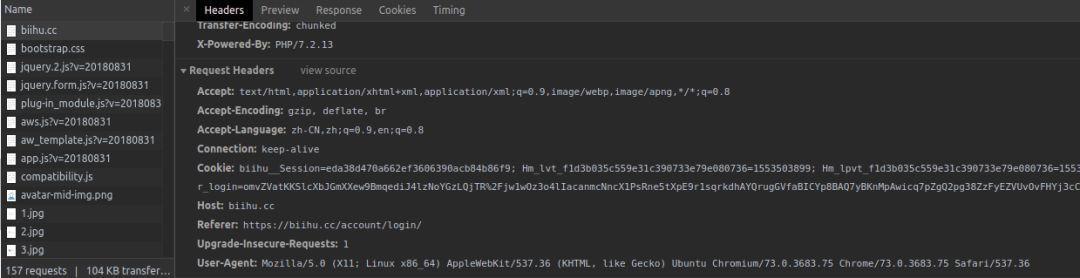
按一下 F12
点击 network 标签
然后登录你的帐号
然后点击其中一个
你就可以看到在 Request Headers 有你的 Cookie
有了 Cookie 之后
我们在代码中直接获取我的个人信息
import requests
headers = {
# 假装自己是浏览器
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/73.0.3683.75 Chrome/73.0.3683.75 Safari/537.36',
# 把你刚刚拿到的Cookie塞进来
'Cookie': 'eda38d470a662ef3606390ac3b84b86f9; Hm_lvt_f1d3b035c559e31c390733e79e080736=1553503899; biihu__user_login=omvZVatKKSlcXbJGmXXew9BmqediJ4lzNoYGzLQjTR%2Fjw1wOz3o4lIacanmcNncX1PsRne5tXpE9r1sqrkdhAYQrugGVfaBICYp8BAQ7yBKnMpAwicq7pZgQ2pg38ZzFyEZVUvOvFHYj3cChZFEWqQ%3D%3D; Hm_lpvt_f1d3b035c559e31c390733e79e080736=1553505597',
}
session = requests.Session()
response = session.get('https://biihu.cc/people/wistbean%E7%9C%9F%E7%89%B9%E4%B9%88%E5%B8%85', headers=headers)
print(response.text)
运行后可以发现不用登录就可以直接拿到自己的个人信息了
<!DOCTYPE html> <html> <head> <meta content="text/html;charset=utf-8" http-equiv="Content-Type" /> <meta content="width=device-width, initial-scale=1.0, maximum-scale=1.0, user-scalable=no" name="viewport" /> <meta http-equiv="X-UA-Compatible" content="IE=edge,Chrome=1" /> <meta name="renderer" content="webkit" /> <title>小帅b真特么帅 的个人主页 - 逼乎</title> <meta name="keywords" content="逼乎,问答,装逼,逼乎网站" /> <meta name="description" content="逼乎 ,与世界分享你的装逼技巧与见解" /> <base href="https://biihu.cc/" rel="external nofollow" /><!--[if IE]></base><![endif]--> <link rel="stylesheet" type="text/css" href="https://biihu.cc/static/css/bootstrap.css" rel="external nofollow" /> <link rel="stylesheet" type="text/css" href="https://biihu.cc/static/css/icon.css" rel="external nofollow" /> <link href="https://biihu.cc/static/css/default/common.css?v=20180831" rel="external nofollow" rel="stylesheet" type="text/css" /> <link href="https://biihu.cc/static/css/default/link.css?v=20180831" rel="external nofollow" rel="stylesheet" type="text/css" /> <link href="https://biihu.cc/static/js/plug_module/style.css?v=20180831" rel="external nofollow" rel="stylesheet" type="text/css" /> <link href="https://biihu.cc/static/css/default/user.css?v=20180831" rel="external nofollow" rel="stylesheet" type="text/css" /> <link href="https://biihu.cc/static/css/mood/mood.css" rel="external nofollow" rel="stylesheet" type="text/css" /> <script type="text/javascript"> var _02AEC94D5CA08B39FC0E1F7CC220F9B4="a5359326797de302bfc9aa6302c001b8"; var G_POST_HASH=_02AEC94D5CA08B39FC0E1F7CC220F9B4; var G_INDEX_SCRIPT = ""; var G_SITE_NAME = "逼乎"; var G_BASE_URL = "https://biihu.cc"; var G_STATIC_URL = "https://biihu.cc/static"; var G_UPLOAD_URL = "/uploads"; var G_USER_ID = "188"; var G_USER_NAME = "666"; var G_UPLOAD_ENABLE = "Y"; var G_UNREAD_NOTIFICATION = 0; var G_NOTIFICATION_INTERVAL = 100000; var G_CAN_CREATE_TOPIC = "1"; var G_ADVANCED_EDITOR_ENABLE = "Y"; var FILE_TYPES = "jpg,jpeg,png,gif,zip,doc,docx,rar,pdf,psd"; </script> <script src="https://biihu.cc/static/js/jquery.2.js?v=20180831" type="text/javascript"></script>
第二招

表单请求大法
很简单
就是通过抓包
获取请求登录的时候需要用到的用户名密码参数
然后以表单的形式请求服务器
如果你细心一点的话应该会知道之前说过拉
具体在这
去看下
我就不多说了
第三招

Selenium 自动登录法
获取到两个输入框的元素
再获取到登录按钮
往输入框写你的帐号密码
然后自动点击一下登录
username = WAIT.until(EC.presence_of_element_located((By.CSS_SELECTOR, "帐号的selector")))
password = WAIT.until(EC.presence_of_element_located((By.CSS_SELECTOR, "密码的selector")))
submit = WAIT.until(EC.element_to_be_clickable((By.XPATH, '按钮的xpath')))
username.send_keys('你的帐号')
password.send_keys('你的密码')
submit.click()
登录完之后拿到 Cookie
cookies = webdriver.get_cookies()
有了 Cookie 你就可以拿到你想要的数据了,希望对你有帮助
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。