python使用tomorrow实现多线程的例子
如下所示:
import time,requestes
from tomorrow import threads
@threads(10)#使用装饰器,这个函数异步执行
def download(url):
return requests.get(url)
def main():
start = time.time()
urls = [
'https://pypi.org/project/tomorrow/0.2.0/',
'https://www.cnblogs.com/pyld/p/4716744.html',
'http://www.xicidaili.com/nn/10',
'http://baidu.com',
'http://www.bubuko.com/infodetail-1028793.html?yyue=a21bo.50862.201879',
]
responses = [download(i) for i in urls]
end = time.time()
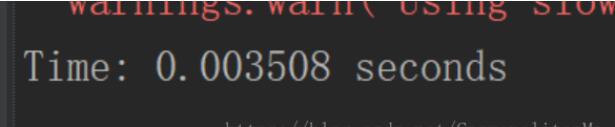
print("Time: %f seconds" % (end - start))
if __name__=="__main__":
main()
不使用多线程:

使用多线程:
以上这篇python使用tomorrow实现多线程的例子就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。