Python逐行读取文件中内容的简单方法
项目开发中文件的读写是必不可少的
下面来简单介绍一下文件的读
读文件,首先我们要有文件
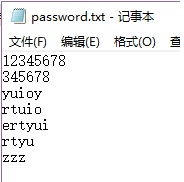
那我首先自己创建了一个文本文件password.txt
内容如下:
下面先贴上代码,然后对其进一步解释:
# coding:utf-8
path = r"C:\Users\Administrator\Desktop\CSDN博客草稿\文件的读\password.txt"
#传入要读的文件路径
file = open(path,"r",encoding="utf-8",errors="ignore")
"""
open表示打开你要执行的文件用读的方式打开
第一个参数是上面的文件path路径,第二个是所要执行的操作,(r)代表读,
#encoding="utf-8表示指定编码为“utf-8”,errors="ignore"表示读的时候遇到错误忽略
"""
while True:
mystr = file.readline()#表示一次读取一行
if not mystr:
#读到数据最后跳出,结束循环。数据的最后也就是读不到数据了,mystr为空的时候
break
print(mystr,end="")#打印每次读到的内容
运行结果如下:

这里简单说一下代码逻辑:
1)首先,你要创建一个文件,或者已存在的文件
文件都没有的话,一切就免谈了。
3)open方法通过你传入的路径,提供的r只读参数
用只读方式打开这个文件。
4)文件打开后,我们就可以写个循环,一行一行读取
并把读取到的数据打印出来。
其中为什么用到end=”“,:
因为print自带换行,
我们读的每一行中也有换行符存在,
默认会换两次行,
只是为了好看,我才加上end=””
让print打印不换行的,
这样就只有一个换行符.
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对【听图阁-专注于Python设计】的支持。如果你想了解更多相关内容请查看下面相关链接