利用python-pypcap抓取带VLAN标签的数据包方法
1、背景介绍
在采用通常的socket抓包方式下,操作系统会自动将收到包的VLAN信息剥离,导致上层应用收到的包不会含有VLAN标签信息。而libpcap虽然是基于socket实现抓包,但在收到数据包后,会进一步恢复出剥离的VLAN信息,能够满足需要抓取带VLAN标签信息的数据包的需求场景。
python-pypcap包是对libpcap库的python语言封装,本文主要介绍如果利用python-pypcap在网络接口抓取带VLAN标签的数据包。
2、环境准备
libpcap-0.9.4
python-pypcap-1.15,该包依赖libpcap-0.9.4
可以通过在python交互式环境下运行import pcap,如果导入成功,说明python-pypcap-1.15已成功安装。
3、抓包实现
pypcap包封装了libpcap提供的许多接口函数,简单的抓包可以采用如下几个步骤完成:
1)Open a handle to a packetcapture descriptor.
fpcap = pcap.pcap(name=iface)
指定从iface接口抓包,此处可以添加其他相关抓包参数,大家可以参考对pcap.pcap类的说明。
2)设置过滤规则
fpcap.setfilter('inbound')
此处inbound表示抓取所有发送到该接口的包,不抓取从该接口发送出的数据包,规则的设置同tcpdump抓包设置过滤规则相同。
3)调用loop函数循环抓包
fpcap.loop(callback,None)
源文件中对loop函数的说明如下:

此处需要说明的是,在实际使用中发现提供了cnt参数后程序运行会报错,而不加cnt参数可以成功运行,即采用fpcap.loop(callback,None)。
4)实现包处理回调函数callback
callback函数声明如下:

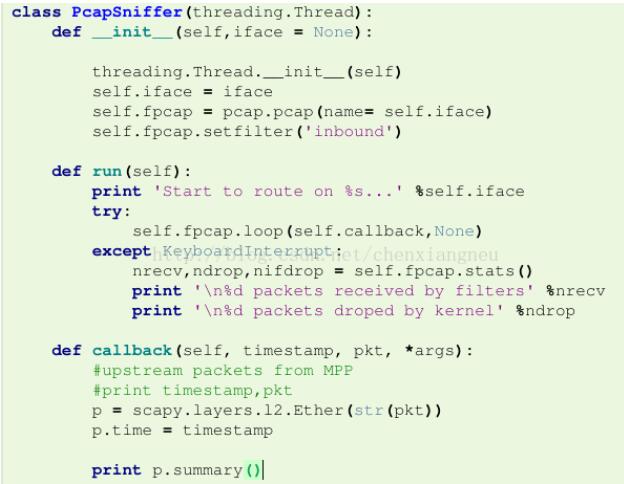
这里需要说明的是,参数timestamp和pkt会由loop函数自动传入,pkt表示数据包,但其类型是buffer类型,这里可以采用图中的scapy.layers.l2.Ether(str(pkt))将pkt转化为scapy的Ether类型[如果包为dot3类型的,也将自动转化为Dot3类型的对象,此处针对isis协议]。然后再通过p.time = timestamp将时间戳信息更新到包中。后续就可以按照处理scapy的Ether类型包的方式进行进一步包处理。
4、示例
下述代码实现了一个线程类,能够在指定的接口iface上抓取进入该接口的包并打印包概要信息。
以上这篇利用python-pypcap抓取带VLAN标签的数据包方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。