Python爬虫使用代理IP的实现
使用爬虫时,如果目标网站对访问的速度或次数要求较高,那么你的 IP 就很容易被封掉,也就意味着在一段时间内无法再进行下一步的工作。这时候代理 IP 能够给我们带来很大的便利,不管网站怎么封,只要能找到一个新的代理 IP 就可以继续进行下一步的研究。
目前很多网站都提供了一些免费的代理 IP 供我们使用,当然付费的会更好用一点。本文除了展示怎样使用代理 IP,也正好体验一下前面文章中搭建的代理 IP 池,不知道的可以点击这里:Python搭建代理IP池(一)- 获取 IP。只要访问代理池提供的接口就可以获取到代理 IP 了,接下来就看怎样使用吧!
测试的网址是:http://httpbin.org/get,访问该站点可以得到请求的一些相关信息,其中 origin 字段就是客户端的 IP,根据它来判断代理是否设置成功,也就是是否成功伪装了IP
获取 IP
代理池使用 Flask 提供了获取的接口:http://localhost:5555/random
只要访问这个接口再返回内容就可以拿到 IP 了
Urllib
先看一下 Urllib 的代理设置方法:
from urllib.error import URLError
import urllib.request
from urllib.request import ProxyHandler, build_opener
# 获取IP
ip_response = urllib.request.urlopen("http://localhost:5555/random")
ip = ip_response.read().decode('utf-8')
proxy_handler = ProxyHandler({
'http': 'http://' + ip,
'https': 'https://' + ip
})
opener = build_opener(proxy_handler)
try:
response = opener.open('http://httpbin.org/get')
print(response.read().decode('utf-8'))
except URLError as e:
print(e.reason)
运行结果:
{
"args": {},
"headers": {
"Accept-Encoding": "identity",
"Host": "httpbin.org",
"User-Agent": "Python-urllib/3.7"
},
"origin": "108.61.201.231, 108.61.201.231",
"url": "https://httpbin.org/get"
}
Urllib 使用 ProxyHandler 设置代理,参数是字典类型,键名为协议类型,键值是代理,代理前面需要加上协议,即 http 或 https,当请求的链接是 http 协议的时候,它会调用 http 代理,当请求的链接是 https 协议的时候,它会调用https代理,所以此处生效的代理是:http://108.61.201.231 和 https://108.61.201.231
ProxyHandler 对象创建之后,再利用 build_opener() 方法传入该对象来创建一个 Opener,这样就相当于此 Opener 已经设置好代理了,直接调用它的 open() 方法即可使用此代理访问链接
Requests
Requests 的代理设置只需要传入 proxies 参数:
import requests
# 获取IP
ip_response = requests.get("http://localhost:5555/random")
ip = ip_response.text
proxies = {
'http': 'http://' + ip,
'https': 'https://' + ip,
}
try:
response = requests.get('http://httpbin.org/get', proxies=proxies)
print(response.text)
except requests.exceptions.ConnectionError as e:
print('Error', e.args)
运行结果:
{
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.21.0"
},
"origin": "47.90.28.54, 47.90.28.54",
"url": "https://httpbin.org/get"
}
Requests 只需要构造代理字典然后通过 proxies 参数即可设置代理,比较简单
Selenium
import requests
from selenium import webdriver
import time
# 借助requests库获取IP
ip_response = requests.get("http://localhost:5555/random")
ip = ip_response.text
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--proxy-server=http://' + ip)
browser = webdriver.Chrome(chrome_options=chrome_options)
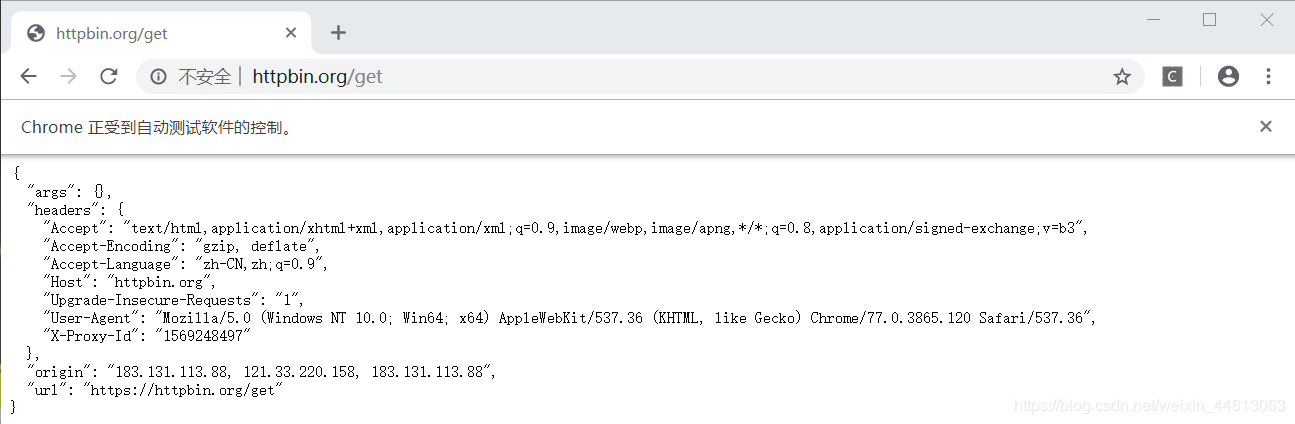
browser.get('http://httpbin.org/get')
time.sleep(5)
运行结果:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。