python3 requests库实现多图片爬取教程
最近对爬虫比较感兴趣,所以就学了一下,看人家都在网上爬取那么多美女图片养眼,我也迫不及待的试了一下,不多说,切入正题。
其实爬取图片和你下载图片是一个样子的,都是操作链接,也就是url,所以当我们确定要爬取的东西后就要开始寻找url了,所以先打开百度图片搜一下
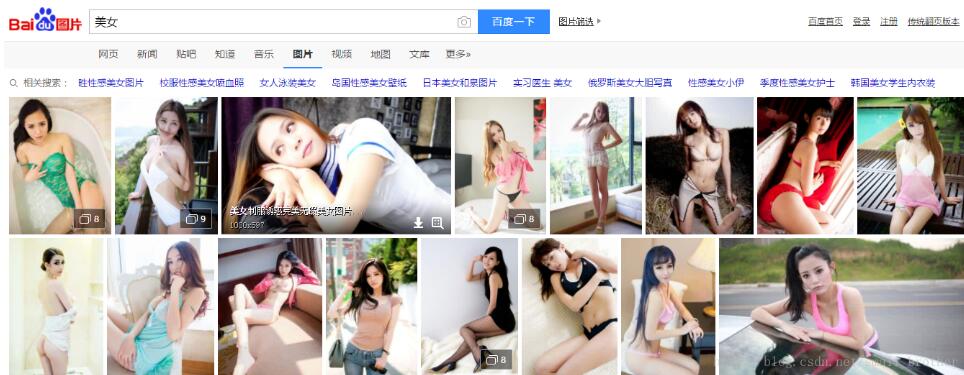
然后使用浏览器F12进入开发者模式,或者右键检查元素
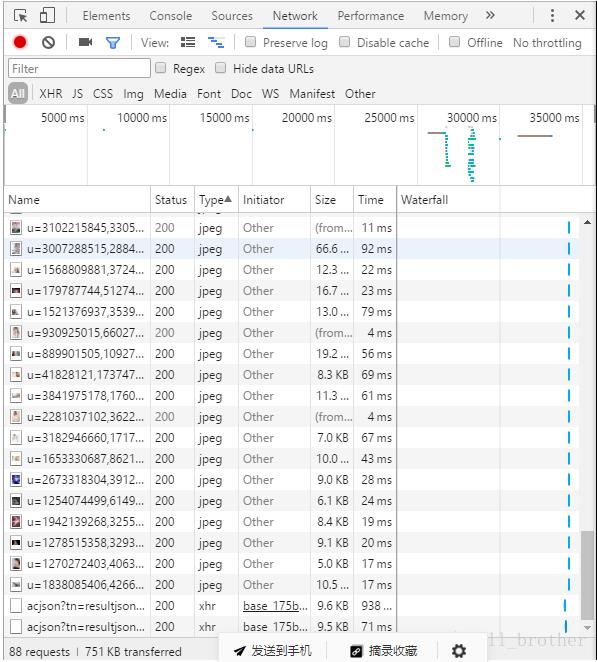
注意看xhr,点开观察有什么不一样的(如果没有xhr就在网页下滑)
第一个是这样的
第二个是这样的
注意看,pn是不是是30的倍数,而此时网页图片的数量也在增多,发现了这个,进url看一下,首先看原网页源码
view-source:http://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=index&fr=&hs=0&xthttps=111121&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=%E7%BE%8E%E5%A5%B3&oq=%E7%BE%8E%E5%A5%B3&rsp=-1
再看看两个Requests URL的页面,发现都是这样的
不用管他,找我们要的信息,ObjURL,"ObjURL":"http:\/\/image.tianjimedia.com\/uploadimages\/2015\/131\/34\/545szi3x5s84_680x500.jpg"
就是这个,好,现在东西都找到在哪了,写程序咯
import re
import requests
import os
name=input('输入文件夹名称:')
robot='C:/Users/lenovo/Desktop/'+name+'/'
kv={'user-agent':'mozilla/5.0'}
#获取url对应的源码页面
def getHTMLText(url):
try:
r=requests.get(url,timeout=30,headers=kv)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ''
#解析url源码页面
def parserHTML(html):
#正则表达式为获取ObjURL
pattern=r'"ObjURL":"(.*?)"'
reg=re.compile(pattern)
urls=re.findall(reg,html)
return urls
#下载图片
def download(List):
for url in List:
try:
path=robot+url.split('/')[-1]
url=url.replace('\\','')
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
if not os.path.exists(robot):
os.makedirs(robot)
if not os.path.exists(path):
with open(path,'wb') as f:
f.write(r.content)
f.close()
print(path+' 文件保存成功')
else:
print('文件已经存在')
except:
continue
#通过Requests URL请求到更多的url源码页面
def getmoreurl(num,word):
ur=[]
url=r'http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord={word}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word={word}&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&cg=girl&pn={pn}&rn=30'
for x in range(1,num+1):
#word为搜索关键词,num为想获取的页面数量
u=url.format(word=word,pn=30*x)
ur.append(u)
return ur
def main():
n=int(input('输入想下载多少张图片(n*30):'))
word=input('输入想下载的图片:')
#初始页面url
url='http://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1499773676062_R&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word={word}'.format(word=word)
html=getHTMLText(url)
urls=parserHTML(html)
download(urls)
#下面操作获取的更多页面图片
url1=getmoreurl(n,word)
for i in range(n):
html1=getHTMLText(url1[i])
urls1=parserHTML(html1)
download(urls1)
main()
然后试一试效果
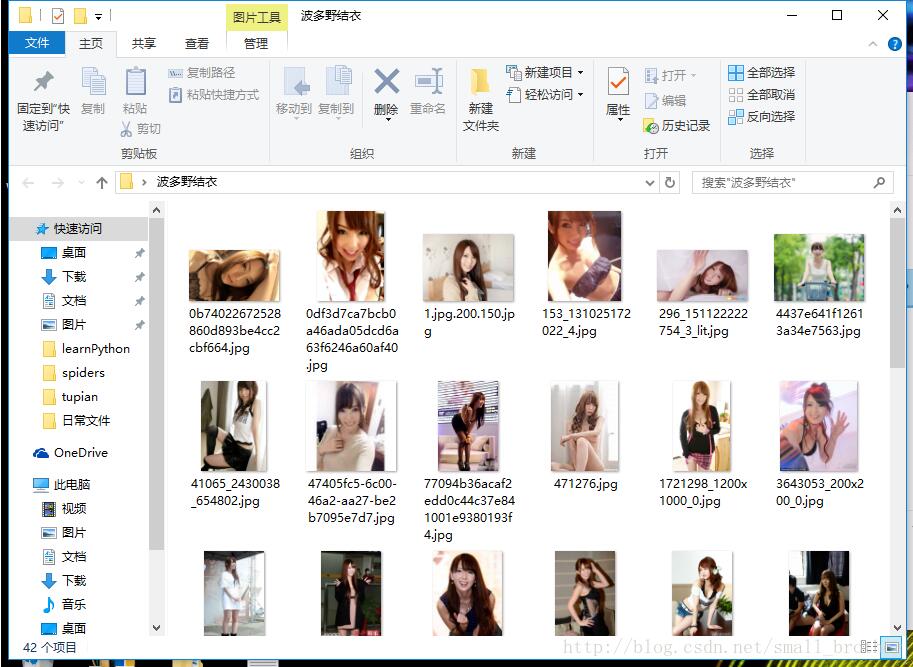
我知道你们会原谅我的
以上这篇python3 requests库实现多图片爬取教程就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持【听图阁-专注于Python设计】。