Python里字典的基本用法(包括嵌套字典)
Python字典的基本用法
创建字典:
myDict1 = {
'薛之谦':'我叫薛之谦',
'吴青峰':'我叫吴青峰',
'李宇春':'我叫李宇春',
'花花':'我叫花花',
'赵雷':'我叫赵雷'
}
emptyDict = {}
myDict2 = dict(薛之谦 = '我叫薛之谦',吴青峰 = '我叫吴青峰')
myDict3 = dict((('薛之谦','我叫薛之谦'),('吴青峰','我叫吴青峰')))
print(myDict1 ,'\n', myDict2 ,'\n', myDict3)
结果:

获取字典里的内容:
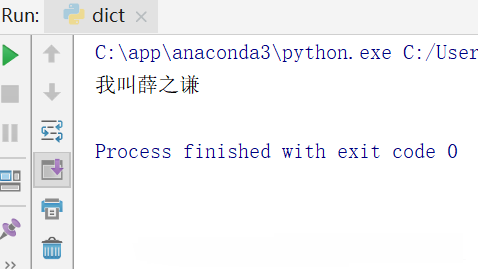
#字典获取内容 print(myDict1['薛之谦'])
打印结果:
修改或者新添:
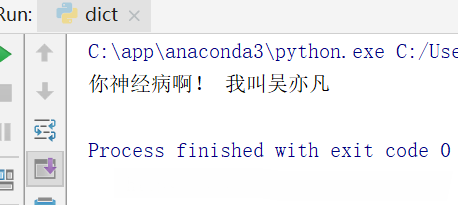
#修改字典内容 myDict1['薛之谦'] = '你神经病啊!' #存在直接修改 myDict1['吴亦凡'] = '我叫吴亦凡' #不存在的直接添加 print(myDict1['薛之谦'] ,myDict1['吴亦凡'])
结果:
删除字典里的内容:
#删除字典内容
myDict1.pop("赵雷") #标准删除姿势
print("删除赵雷后:",myDict1)
del myDict1['花花'] # 换个姿势删除
print("删除花花后:",myDict1)
myDict1.popitem() #随机删除一个
print("随机删除一个后",myDict1)
结果:

嵌套字典:
#多级字典(嵌套字典)
FamousDict = {
'薛之谦':{
'身高':178,
'体重':130,
'口头禅':['你神经病啊!','我不要面子啊'] #相应的值可以是 一个列表
},
'吴青峰':{
'身高':170,
'体重':120,
'口头禅':['我叫吴青峰','你好']
}
}
#访问多级字典:
print('薛之谦的体重为:',FamousDict['薛之谦']['体重'],'斤')
#修改薛之谦体重为125
FamousDict['薛之谦']['体重'] = 125
print('减肥后的薛之谦体重为:',FamousDict['薛之谦']['体重'],'斤')
#新添薛之谦腰围100
FamousDict['薛之谦']['腰围'] = 100
print('薛之谦的腰围为:',FamousDict['薛之谦']['腰围'],'cm')
#多级字典删除
FamousDict['吴青峰'].pop('身高') #标准删除
del FamousDict['吴青峰']['体重'] #另一个删除方法
print('关于吴青峰现在只剩下:',FamousDict['吴青峰'])
结果为:

总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对【听图阁-专注于Python设计】的支持。如果你想了解更多相关内容请查看下面相关链接