PyCharm搭建Spark开发环境实现第一个pyspark程序
一, PyCharm搭建Spark开发环境
Windows7, Java1.8.0_74, Scala 2.12.6, Spark 2.2.1, Hadoop2.7.6
通常情况下,Spark开发是基于Linux集群的,但这里作为初学者并且囊中羞涩,还是在windows环境下先学习吧。
参照这个配置本地的Spark环境。
之后就是配置PyCharm用来开发Spark。本人在这里浪费了不少时间,因为百度出来的无非就以下两种方式:
1.在程序中设置环境变量
import os
import sys
os.environ['SPARK_HOME'] = 'C:\xxx\spark-2.2.1-bin-hadoop2.7'
sys.path.append('C:\xxx\spark-2.2.1-bin-hadoop2.7\python')
2.在Edit Configuration中添加环境变量
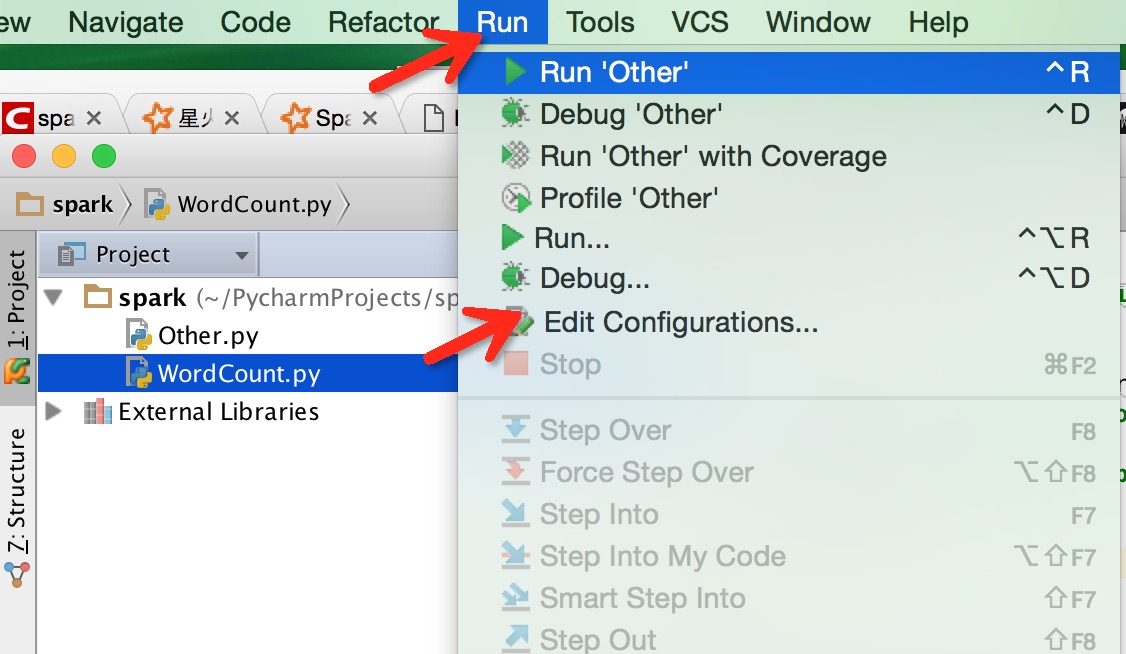
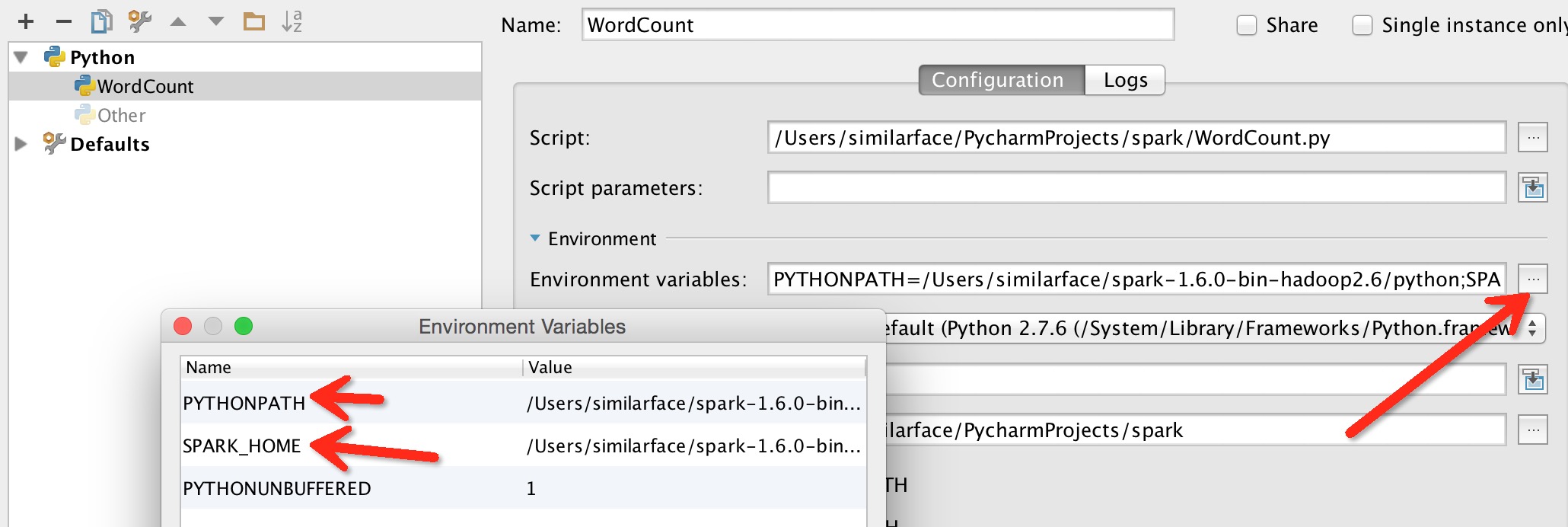
不过还是没有解决程序中代码自动补全。
想了半天,观察到spark提供的pyspark很像单独的安装包,应该可以考虑将pyspark包放到python的安装目录下,这样也就自动添加到之前所设置的pythonpath里了,应该就能实现pyspark的代码补全提示。
将spark下的pyspark包放到python路径下(注意,不是spark下的python!)
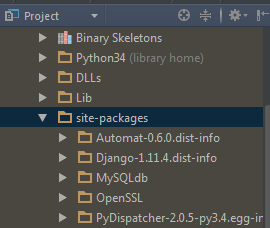
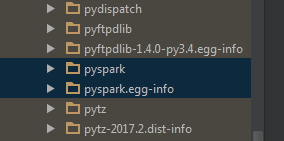
最后,实现了pyspark代码补全功能。
二.第一个pyspark程序
作为小白,只能先简单用下python+pyspark了。
数据:Air Quality in Madrid (2001-2018)
需求:根据历史数据统计出每个月平均指标值
import os
import re
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession.builder.getOrCreate()
df_array = []
years = []
air_quality_data_folder = "C:/xxx/spark/air-quality-madrid/csvs_per_year"
for file in os.listdir(air_quality_data_folder):
if '2018' not in file:
year = re.findall("\d{4}", file)
years.append(year[0])
file_path = os.path.join(air_quality_data_folder, file)
df = spark.read.csv(file_path, header="true")
# print(df.columns)
df1 = df.withColumn('yyyymm', df['date'].substr(0, 7))
df_final = df1.filter(df1['yyyymm'].substr(0, 4) == year[0]).groupBy(df1['yyyymm']).agg({'PM10': 'avg'})
df_array.append(df_final)
pm10_months = [0] * 12
# print(range(12))
for df in df_array:
for i in range(12):
rows = df.filter(df['yyyymm'].contains('-'+str(i+1).zfill(2))).first()
# print(rows[1])
pm10_months[i] += (rows[1]/12)
years.sort()
print(years[0] + ' - ' + years[len(years)-1] + '年,每月平均PM10统计')
m_index = 1
for data in pm10_months:
print(str(m_index).zfill(2) + '月份: ' + '||' * round(data))
m_index += 1
运行结果:
- 2017年,每月平均PM10统计 01月份: |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 02月份: |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 03月份: |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 04月份: |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 05月份: |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 06月份: |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 07月份: |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 08月份: |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 09月份: |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 10月份: |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 11月份: |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 12月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
由以上统计结果,可以看出4月份的PM10最低。
Done!
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。