pandas 缺失值与空值处理的实现方法
1.相关函数
- df.dropna()
- df.fillna()
- df.isnull()
- df.isna()
2.相关概念
空值:在pandas中的空值是""
缺失值:在dataframe中为nan或者naT(缺失时间),在series中为none或者nan即可
3.函数具体解释
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
函数作用:删除含有空值的行或列
axis:维度,axis=0表示index行,axis=1表示columns列,默认为0
how:"all"表示这一行或列中的元素全部缺失(为nan)才删除这一行或列,"any"表示这一行或列中只要有元素缺失,就删除这一行或列
thresh:一行或一列中至少出现了thresh个才删除。
subset:在某些列的子集中选择出现了缺失值的列删除,不在子集中的含有缺失值得列或行不会删除(有axis决定是行还是列)
inplace:刷选过缺失值得新数据是存为副本还是直接在原数据上进行修改。
例子:
df = pd.DataFrame({"name": ['Alfred', 'Batman', 'Catwoman'],
"toy": [np.nan, 'Batmobile', 'Bullwhip'],
"born": [pd.NaT, pd.Timestamp("1940-04-25"),pd.NaT]})
print df

默认参数:删除行,只要有空值就会删除,不替换。
print df.dropna() print df

print "delete colums" print df.dropna(axis=1) #delete col

print "所有值全为缺失值才删除" print df.dropna(how='all')

print "至少出现过两个缺失值才删除" print df.dropna(thresh=2)

print "删除这个subset中的含有缺失值的行或列" print df.dropna(subset=['name', 'born'])

DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs)
函数作用:填充缺失值
value:需要用什么值去填充缺失值
axis:确定填充维度,从行开始或是从列开始
method:ffill:用缺失值前面的一个值代替缺失值,如果axis =1,那么就是横向的前面的值替换后面的缺失值,如果axis=0,那么则是上面的值替换下面的缺失值。backfill/bfill,缺失值后面的一个值代替前面的缺失值。注意这个参数不能与value同时出现
limit:确定填充的个数,如果limit=2,则只填充两个缺失值。
示例:
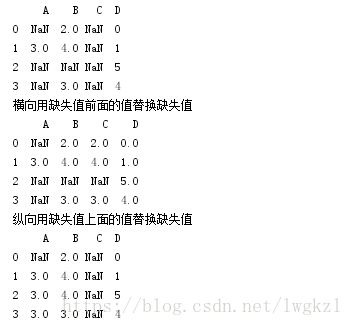
df = pd.DataFrame([[np.nan, 2, np.nan, 0],
[3, 4, np.nan, 1],
[np.nan, np.nan, np.nan, 5],
[np.nan, 3, np.nan, 4]],
columns=list('ABCD'))
print df
print "横向用缺失值前面的值替换缺失值"
print df.fillna(axis=1,method='ffill')
print "纵向用缺失值上面的值替换缺失值"
print df.fillna(axis=0,method='ffill')
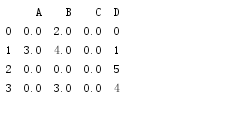
print df.fillna(0)
不同的列用不同的值填充:
![]()
对每列出现的替换值有次数限制,此处限制为一次

DataFrame.isna()
判断是不是缺失值:
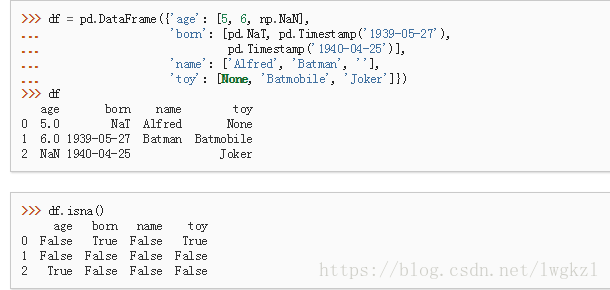
isnull同上。
替换空值:
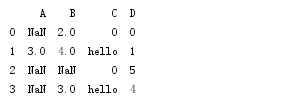
df = pd.DataFrame([[np.nan, 2, np.nan, 0],
[3, 4, "", 1],
[np.nan, np.nan, np.nan, 5],
[np.nan, 3, "", 4]],
columns=list('ABCD'))
print df

如上,缺失值是NAN,空值是没有显示。
替换空值代码:需要把含有空值的那一列提出来单独处理,然后在放进去就好。
clean_z = df['C'].fillna(0) clean_z[clean_z==''] = 'hello' df['C'] = clean_z print df
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持【听图阁-专注于Python设计】。


