Python+Selenium+phantomjs实现网页模拟登录和截图功能(windows环境)
本文全部操作均在windows环境下
安装 Python
Python是一种跨平台的计算机程序设计语言,它可以运行在Windows、Mac和各种Linux/Unix系统上。是一种面向对象的动态类型语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越来越多被用于独立的、大型项目的开发
去Python的官网 www.python.org 下载安装
安装时勾选pip (python包管理工具),同时安装pip
python安装好之后,打开命令行工具cmd,输入“python -V”,然后敲回车,如果出现python版本号,则表示安装成功
安装 selenium
selenium 是一个用于Web应用程序测试的工具。selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。selenium 是一套完整的web应用程序测试系统,包含了测试的录制(selenium IDE),编写及运行(Selenium Remote Control)和测试的并行处理(Selenium Grid)
通过python包管理工具pip安装
pip install selenium
安装 phantomjs
phantomJS是一个基于webkit的javaScript API。它使用QtWebKit作为它核心浏览器的功能,使用webkit来编译解释执行javaScript代码。任何你可以基于在webkit浏览器做的事情,它都能做到。它不仅是个隐性的浏览器,提供了诸如css选择器、支持wen标准、DOM操作、json、HTML5等,同时也提供了处理文件I/O的操作,从而使你可以向操作系统读写文件等。phantomJS的用处可谓非常广泛诸如网络监测、网页截屏、无需浏览器的wen测试、页面访问自动化等
phantomjs安装链接 www.phantomjs.org
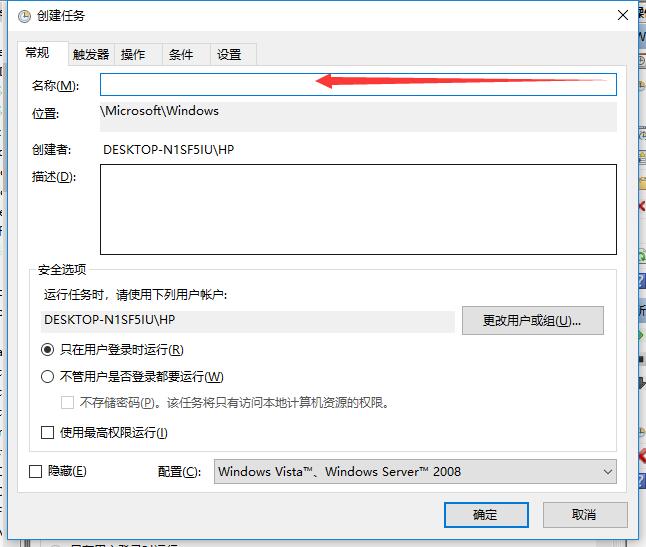
在桌面创建demo文件夹,创建demo.py文件,当做我们的脚本文件,创建img文件夹用来存放截取的图片demo.py:
# coding=utf-8
# 导入网页驱动软件
from selenium import webdriver
# 导入WebDriverWait等待模块
from selenium.webdriver.support.wait import WebDriverWait
import time
# 调用环境变量指定的PhantomJS浏览器创建浏览器对象
# 括号内为phantomjs安装位置
driver = webdriver.PhantomJS(executable_path="D:\\Python27\\Scripts\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe")
# 访问的网址(以央视网为例)
driver.get("http://www.cctv.com/")
# 最大化浏览器
driver.maximize_window()
# 模拟点击登录按钮登录弹出登录框(后面有定位元素方法介绍)
driver.find_elements_by_xpath('//span[@class="btn_icon"]')[1].click()
# 等待登录页面加载完成,WebDriverWait (后面有等待方法介绍)
WebDriverWait(driver, 10, 0.5).until(lambda diver:driver.find_element_by_xpath('//a[@class="dl"]'),message="")
time.sleep(2)
# 截取登录框的页面保存到相应位置
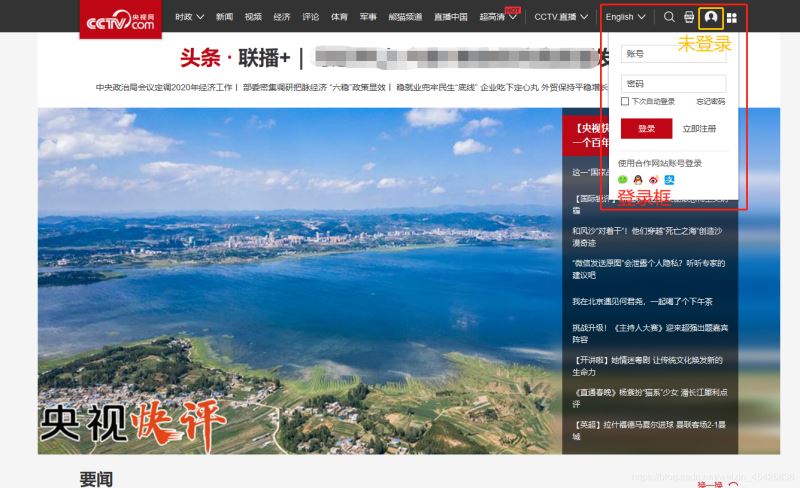
driver.save_screenshot('demo\\img\\login1.png')
# 定位登录页面用户名和密码元素并模拟填入用户名和密码
driver.find_element_by_name("username").send_keys('xxxxxxxxxxx')
driver.find_element_by_name("passwd_view").send_keys('xxxxxxxxxxx')
# 模拟点击登录按钮登录
driver.find_element_by_link_text('登录').click()
WebDriverWait(driver, 10, 0.5).until(lambda diver:driver.find_elements_by_xpath('//span[@class="btn_icon"]'),message="")
time.sleep(2)
# 截取登录后的页面保存到相应位置
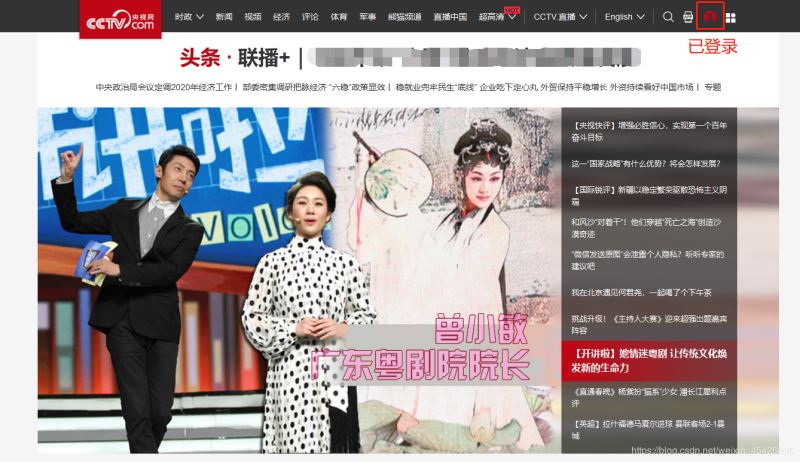
driver.save_screenshot('demo\\img\\login2.png')
# 模拟点击按钮跳转体育页面
driver.find_element_by_link_text('体育').click()
WebDriverWait(driver, 10, 0.5).until(lambda diver:driver.find_element_by_link_text('CBA'),message="")
time.sleep(2)
# 截取体育页面保存到相应位置
driver.save_screenshot('demo\\img\\sport.png')
# 退出驱动关闭所有窗口
driver.quit()
运行python脚本
打开命令行窗口cmd,切换到demo.py文件的路径下,输入
python demo.py
脚本运行后会自动填写我们设定好的用户名密码并登录,截取设置好的页面并保存到img文件夹
登录框的页面截图:
登录后的页面截图:
体育页面截图:
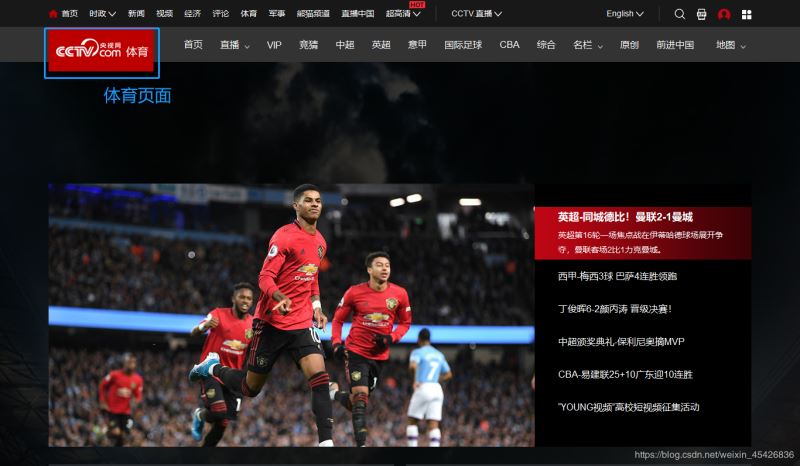
部分方法介绍:区块定位截图(二次截图)方法:
PIL(Python Image Library)是python的第三方图像处理库,PIL功能非常强大,API非常简单易用,已经是Python平台事实上的图像处理标准库了。 PIL只支持python2.x的版本,python3.x的版本需要安装pillow, pillow是一个对PIL友好的分支,但是支持python3.x的版本
python2.x版本下安装PIL进行二次截图
pip install PIL
python3.x版本下安装pillow 进行区块定位截图
pip install pillow
demo.py:
# 导入Image类
from PIL import Image
# 定位需要二次截图区块的元素
img = driver.find_element_by_xpath('//*[@class="weui-img"]')
# 区块元素左上角在网页中的x坐标
left = img.location['x']
# 区块元素左上角在网页中的y坐标
top = img.location['y']
# 区块元素右下角在网页中的x坐标
right = img.location['x'] + img.size['width']
# 区块元素右下角在网页中的y坐标
bottom = img.location['y'] + img.size['height']
# 打开页面的截图
photo = Image.open('demo\\img\\img_page.png')
# 根据区块元素坐标实现二次截图
photo = photo.crop((left, top, right, bottom))
# 保存二次截图
photo.save('demo\\img\\img.png')
WebDriver8种基本元素定位方法:
1. find_element_by_id() 根据id属性进行定位
例如:find_element_by_id(“one”) 定位id为one的元素
2. find_element_by_name() 根据name属性进行定位
例如:find_element_by_name(“one”) 定位name属性为one的元素
3. find_element_by_class_name() 根据class的名字进行定位
例如:find_element_by_class_name(“one”) 定位class为one的元素
4. find_element_by_xpath() xpath是XML路径语言,通过确定xml文档中的元素位置来完成对元素的定位
例如:find_element_by_xpath("//div[@id=‘one']") 定位id为one的div元素
find_element_by_xpath("//*[@class=‘two']") 定位class为two的元素
5. find_element_by_css_selector() 根据css属性进行定位
例如:find_element_by_css_selector("#one") 定位id为one的div元素
find_element_by_css_selector(".two") 定位class为two的元素
6. find_element_by_tag_name () 根据标签名进行定位
例如:find_element_by_tag_name(“input”) 定位input元素
7. find_element_by_link_text() 根据完整a链接文字进行定位find_element_by_partial_link_text() 根据部分a链接文字进行定位
例如:find_element_by_link_text(“新闻”) 定位文字为‘新闻'的a元素
find_element_by_partial_link_text(“闻”) 定位文字包括‘闻'的a元素
8. By定位( 需要导入By类:from selenium.webdriver.common.by import By )
例如:find_element(By.ID,“one”) 定位id为one的元素
find_element(By.NAME,“one”) 定位name属性为one的元素
find_element(By.CLASS_NAME,“one”) 定位class为one的元素
find_element(By.TAG_NAME,“div”) 定位div元素
当定位元素为多个时,使用elements复数定位,即把定位方法中的element换成elements,此时获取到的为相同属性的一组元素,返回一个list队列,然后可以再去定位单个元素
例如:find_elements_by_class_name(“one”)[1] 定位class为one的所有元素中第二个元素
selenium的3种等待方法:
在做自动化测试时,有时下一步的操作会依赖上一步的结果或者内容,上一步操作成功完成之后才能进行下一步操作,此时,我们就需要使用等待,来判断上一步操作是否完成,进而执行下面的操作,例如登录页面进行登录操作时,需要等待登录页面加载成功,才能定位到用户名和密码对应的元素,然后才能填充用户名和密码,进行登录操作。
1. 强制等待time.sleep(s) 强制等待s秒后再进行下面的操作
缺点:不易把控时间,等待时间固定,如果没到设置时间,已经可以进行下面的操作,则需要多余的等待,如果到达设置时间,还没完成上一步操作,下面的操作还无法正常进行,则会直接报错
2. 隐式等待implicitly_wait(s) 在s秒内,上一步操作完成,进行下一步操作,否则等待s秒后,然后进行下一步操作
缺点:如果到达设置时间,还没完成上一步操作,下面的操作还无法正常进行,则会直接报错
3. 显式等待(推荐使用)WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)
等待页面加载完成,找到某个条件发生后再继续执行后续代码,如果超过设置时间检测不到则抛出异常
driver:浏览器驱动
timeout:最长超时时间,默认以秒为单位
poll_frequency:检测的间隔步长,默认为0.5s
ignored_exceptions:超时后的抛出的异常信息,默认抛出NoSuchElementExeception异常
与until()结合使用:
WebDriverWait(driver, s).until(method,message="")
在s秒内,每0.5秒检测一次,如果传入的方法返回为true,进行下一步操作,如果到达设置时间未检测到,下面的操作无法正常运行,则会直接报错
总结
以上所述是小编给大家介绍的Python+Selenium+phantomjs实现网页模拟登录和截图功能(windows环境),希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对【听图阁-专注于Python设计】网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!