yipeiwu_com6年前
这篇文章主要介绍了python爬虫 正则表达式解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 - re.I # 忽略大小...
yipeiwu_com6年前
本实例主要进行线程池创建,多线程获取、存储视频文件 梨视频:利用线程池进行视频爬取 #爬取梨视频数据 import requests import re from lxml impo...
yipeiwu_com6年前
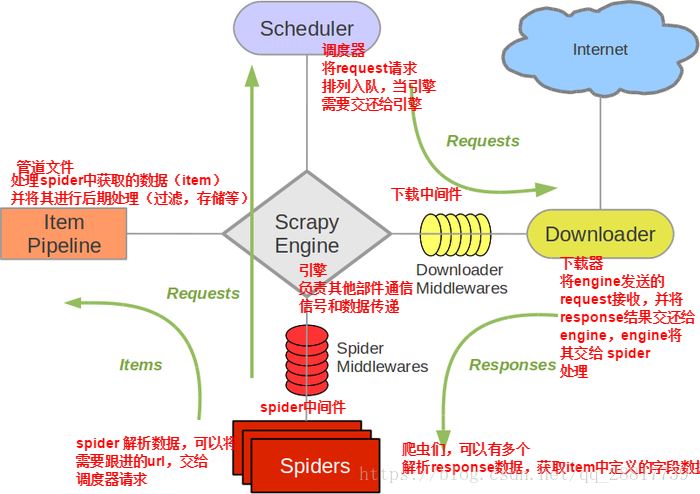
引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值。但是通过...
yipeiwu_com6年前
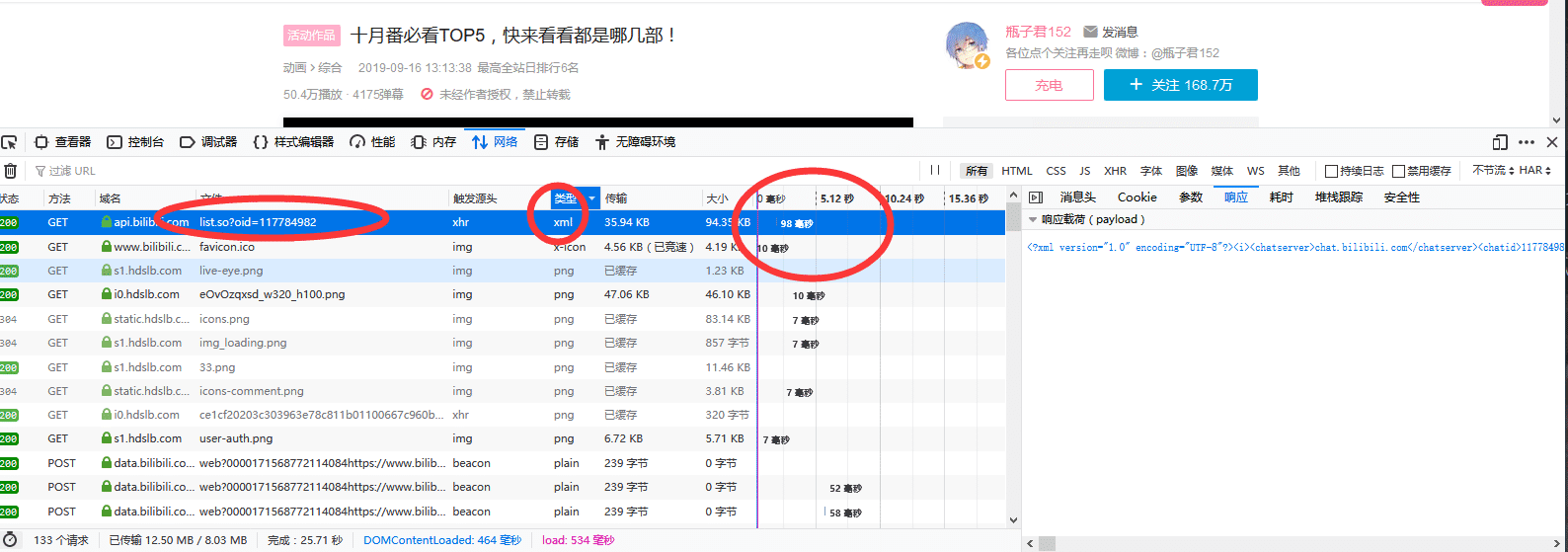
先来思考一个问题,B站一个视频的弹幕最多会有多少? 比较多的会有2000条吧,这么多数据,B站肯定是不会直接把弹幕和这个视频绑在一起的。 也就是说,有一个视频地址为https://www...
yipeiwu_com6年前
综述 本系列文档用于对Python爬虫技术进行简单的教程讲解,巩固自己技术知识的同时,万一一不小心又正好对你有用那就更好了。 Python 版本是3.7.4 urllib库介绍 它是...
yipeiwu_com6年前
爬虫库 使用简单的requests库,这是一个阻塞的库,速度比较慢。 解析使用XPATH表达式 总体采用类的形式 多线程 使用concurrent.future并发模块,建立线程...
yipeiwu_com6年前
很多用Python的人可能都写过网络爬虫,自动化获取网络数据确实是一件令人愉悦的事情,而Python很好的帮助我们达到这种愉悦。然而,爬虫经常要碰到各种登录、验证的阻挠,让人灰心丧气(网...
yipeiwu_com6年前
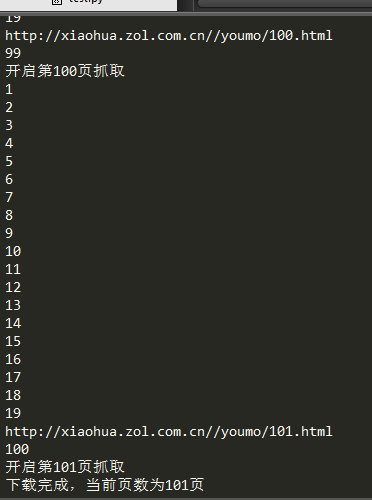
爬取网站为:http://xiaohua.zol.com.cn/youmo/ 查看网页机构,爬取笑话内容时存在如下问题: 1、每页需要进入“查看更多”链接下面网页进行进一步爬取内容每页查...
yipeiwu_com6年前
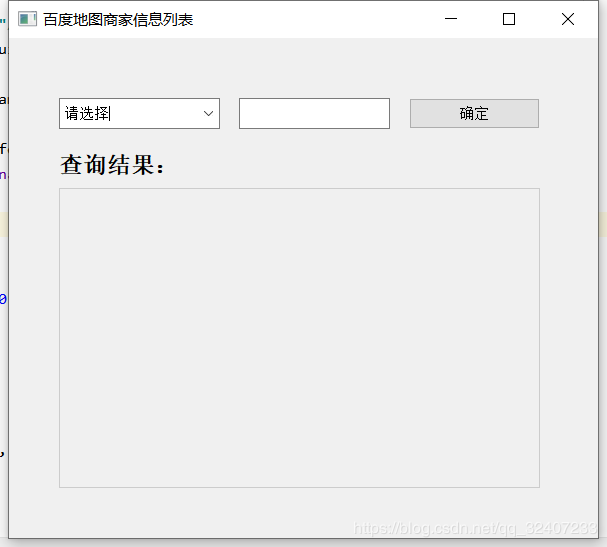
在爬虫百度地图的期间,就为它做了一个界面,运用的是PyQt5。 得到意想不到的结果: # -*- coding: utf-8 -*- # Form implementation...
yipeiwu_com6年前
使用爬虫时,如果目标网站对访问的速度或次数要求较高,那么你的 IP 就很容易被封掉,也就意味着在一段时间内无法再进行下一步的工作。这时候代理 IP 能够给我们带来很大的便利,不管网站怎么...