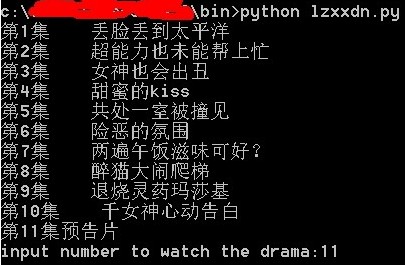
python使用beautifulsoup从爱奇艺网抓取视频播放
复制代码 代码如下:
import sys
import urllib
from urllib import request
import os
from bs4 import BeautifulSoup
class DramaItem:
def __init__(self, num, title, url):
self.num = num
self.title = title
self.url = url
def __str__(self):
return self.num + ' ' + self.title
def openDrama(self):
os.startfile(self.url)
response = urllib.request.urlopen('http://www.iqiyi.com/a_19rrgja8xd.html')
html = response.read()
soup = BeautifulSoup(html)
dramaList = soup.findAll('div', attrs={'class':'list_block1 align_c'})
dramaItems = []
if(dramaList):
lis = dramaList[0].findAll('li')
for li in lis:
ps = li.findAll('p')
description = ps[1].text if len(ps)>1 else ''
num = ps[0].find('a').text
url = ps[0].find('a')['href']
di = DramaItem(num, description, url)
dramaItems.append(di)
for di in dramaItems:
print(di)
diLen = len(dramaItems)
userChoice = int(input('input number to watch the drama:'))
if userChoice >= 1 and userChoice <=diLen:
dramaItems[userChoice-1].openDrama()