相关文章
python进行两个表格对比的方法
如下所示: # -*- coding:utf-8 -*- import xlrd import sys import re import json dict1={} dict2={...

python找出列表中大于某个阈值的数据段示例
该算法实现对列表中大于某个阈值(比如level=5)的连续数据段的提取,具体效果如下: 找出list里面大于5的连续数据段: list = [1,2,3,4,2,3,4,5,6,7,...
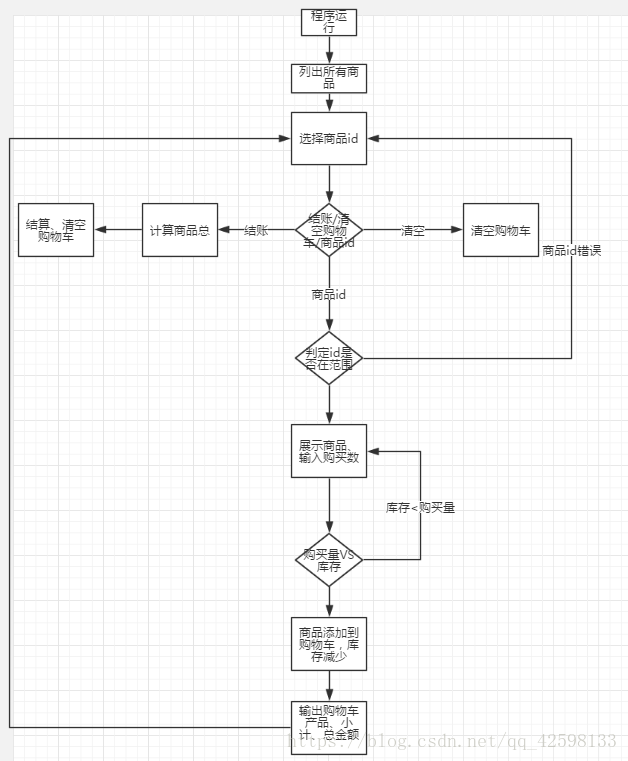
python实现电子产品商店
利用python实现以下功能:基于python下的电子产品商店 电子产品商店 v0.1 请选择商品: ============================= 1 &nbs...
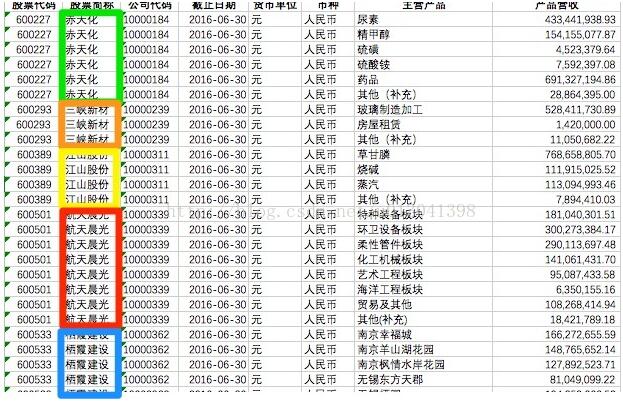
pandas数据预处理之dataframe的groupby操作方法
在数据预处理过程中可能会遇到这样的问题,如下图:数据中某一个key有多组数据,如何分别对每个key进行相同的运算? dataframe里面给出了一个group by的一个操作,对于”g...
Windows下使Python2.x版本的解释器与3.x共存的方法
Python2 和 Python3 是不兼容的,如果碰到无法升级到 Python2 代码,或者同事中有坚守 Python2 阵营的情况,就要考虑 Python2 和 Python3 在系...