Python实现的生成自我描述脚本分享(很有意思的程序)
自我描述的语句指这样一种语句:它的内容就是对它本身的描述。(废话……)比如下面这句句子:
复制代码 代码如下:
这是一段自我描述的语句,除了标点符号外,它共包含125个字符,其中33个“个”,29个“2”,5个“3”,3个“符”,3个“5”,2个“一”,2个“它”,2个“包”,2个“的”,2个“标”,2个“了”,2个“我”,2个“外”,2个“含”,2个“中”,2个“是”,2个“1”,2个“段”,2个“点”,2个“描”,2个“9”,2个“字”,2个“这”,2个“句”,2个“除”,2个“自”,2个“语”,2个“共”,2个“述”,2个“号”,2个“其”。
这句话是我用一段 Python 脚本生成的,生成原理大致如下:
1、给出一个模板,让句子的各个内容知道自己该出现在哪个部位;
2、根据当前信息,生成句子;
3、将当前句子作为输入,再次执行第 2 步的操作;
4、直到句子各部分内容的信息都正确。
简单来说,就是一个不断迭代修正的过程。
其中需要注意的是,每次迭代时应该尽量只改动一个地方,以免两处同时变化相互影响,造成死循环;另外,如果句子中有多处地方需要修正,尽量随机选取一处进行修正,而不要按一定顺序进行修正,同样是为了减少陷入死循环的风险。
不过,即使如此,某些情况下还是有可能陷入死循环,比如如果某一步得到了下面这样的句子:
复制代码 代码如下:
这句很 2 的话包含 3 个“2”。
上面这句话明显是错误的,因为其中只有两个“2”。那么,我们把那个“3”改为“2”,是不是就对了呢?很容易发现,如果我们做了这样的改动之后,句子将变成:
复制代码 代码如下:
这句很 2 的话包含 2 个“2”。
这时,句子中又包含三个“2”了。像这样的句子就似乎无法简单地改为正确的自我描述语句,因为无论如何改都会陷入死循环。
最后,我用来生成最上面的那句自我描述语句的 Python 脚本如下:
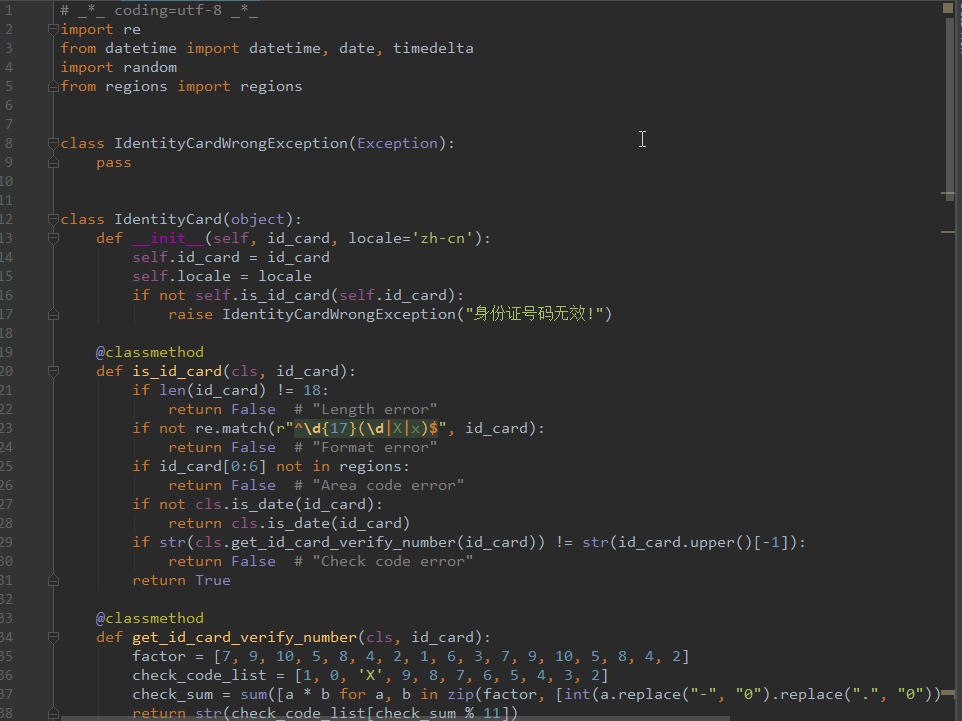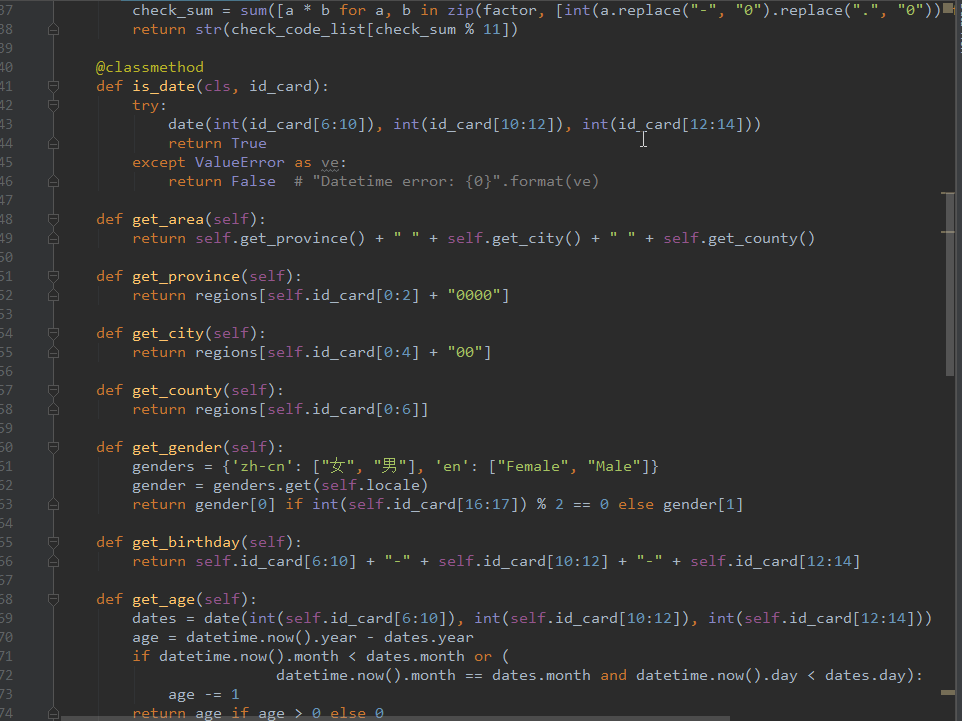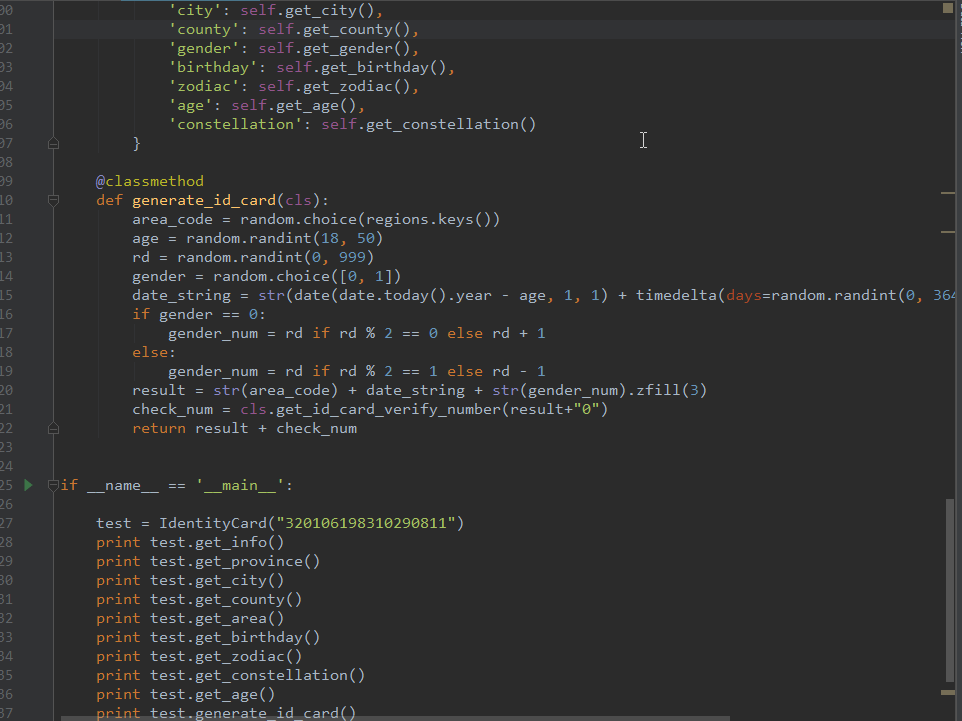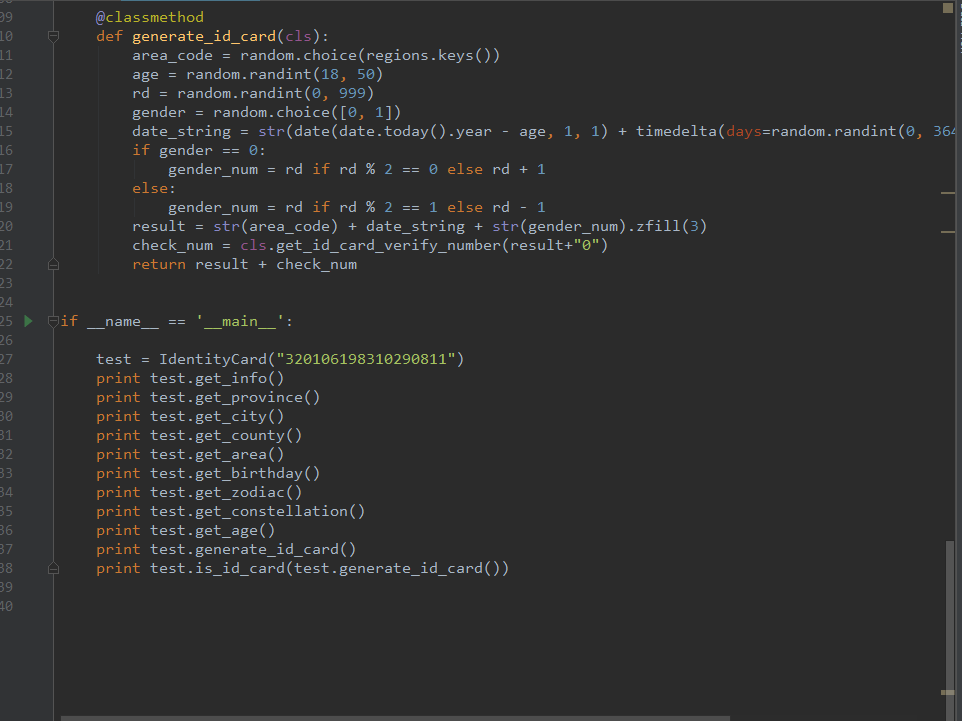
# -*- coding: utf-8 -*-
import random
class SelfDesc(object):
ignore_chars = u",。“”"
def __init__(self, template):
self.template = template
self.length = 0
self.detail = ""
self.content = ""
self.chars = ""
self.char_count = {}
self.makeContent()
self.char_count = self.getCharCount()
self.getCharCount()
self.makeContent()
def __str__(self):
return self.content
def makeContent(self):
self.makeDetail()
self.content = self.template.replace(u"{length}", u"%d" % self.length)
.replace(u"{detail}", self.detail)
self.getChars()
def getChars(self):
chars = self.content
for c in self.ignore_chars:
chars = chars.replace(c, "")
self.chars = chars
return chars
def getLength(self):
self.length = len(self.chars)
def getCharCount(self):
d = {}
for c in self.chars:
if c in self.ignore_chars:
continue
d.setdefault(c, 0)
d[c] += 1
return d
def makeDetail(self):
d = self.char_count
items = d.items()
items.sort(key=lambda x: -x[1])
s = []
for c, n in items:
s.append(u"%d个“%s”" % (n, c))
self.detail = u",".join(s)
def correct(self):
print "-" * 50
char_count = self.getCharCount()
items = char_count.items()
random.shuffle(items)
for c, n in items:
if n <= 1 and c in self.char_count:
del self.char_count[c]
continue
if self.char_count.get(c) == n:
continue
else:
self.char_count[c] = n
return True
else:
len = self.length
self.getLength()
if len != self.length:
return True
return False
def generate(self):
icount = 0
while self.correct():
icount += 1
self.makeContent()
print u"#%d %s" % (icount, self)
def main():
template = u"这是一段自我描述的语句,除了标点符号外,它共包含{length}个字符,其中{detail}。"
sd = SelfDesc(template)
sd.generate()
print u"%s" % sd
if __name__ == "__main__":
main()