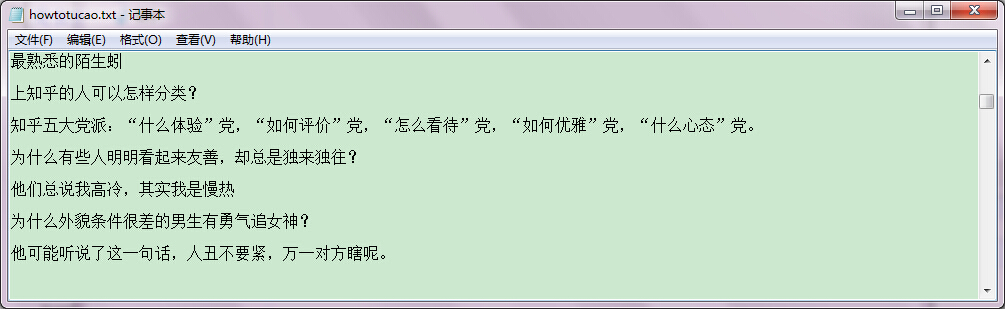
Python实现爬取知乎神回复简单爬虫代码分享
看知乎的时候发现了一个 “如何正确地吐槽” 收藏夹,里面的一些神回复实在很搞笑,但是一页一页地看又有点麻烦,而且每次都要打开网页,于是想如果全部爬下来到一个文件里面,是不是看起来很爽,并且随时可以看到全部的,于是就开始动手了。
工具
1.Python 2.7
2.BeautifulSoup
分析网页
我们先来看看知乎上该网页的情况
网址: ,容易看到,网址是有规律的,page慢慢递增,这样就能够实现全部爬取了。
,容易看到,网址是有规律的,page慢慢递增,这样就能够实现全部爬取了。
再来看一下我们要爬取的内容:
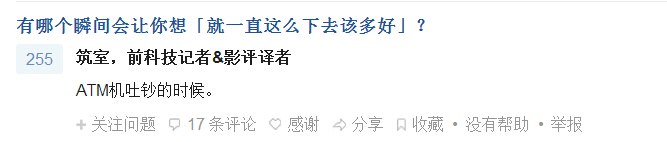 我们要爬取两个内容:问题和回答,回答仅限于显示了全部内容的回答,如下面这种就不能爬取,因为好像无法展开(反正我不会。。),再说答案不全的话爬来也没用,所以就不爬答案不全的了吧。
我们要爬取两个内容:问题和回答,回答仅限于显示了全部内容的回答,如下面这种就不能爬取,因为好像无法展开(反正我不会。。),再说答案不全的话爬来也没用,所以就不爬答案不全的了吧。

好,那么下面我们要找到他们在网页源代码中的位置:
 即我们找到问题的内容包含在<h2 class = "zm-item-title"><a tar...>中,那么我们等会就可以在这个标签里面找问题。
即我们找到问题的内容包含在<h2 class = "zm-item-title"><a tar...>中,那么我们等会就可以在这个标签里面找问题。
然后是回复:
 有两个地方都有回复的内容,因为上面那个的内容还包括了<span..>等一些内容,不方便处理,我们爬下面那个的内容,因为那个里面的内容纯正无污染。
有两个地方都有回复的内容,因为上面那个的内容还包括了<span..>等一些内容,不方便处理,我们爬下面那个的内容,因为那个里面的内容纯正无污染。
代码
好,这时候我们试着写出python代码:
# -*- coding: cp936 -*-
import urllib2
from BeautifulSoup import BeautifulSoup
f = open('howtoTucao.txt','w') #打开文件
for pagenum in range(1,21): #从第1页爬到第20页
strpagenum = str(pagenum) #页数的str表示
print "Getting data for Page " + strpagenum #shell里面显示的,表示已爬到多少页
url = "http://www.zhihu.com/collection/27109279?page="+strpagenum #网址
page = urllib2.urlopen(url) #打开网页
soup = BeautifulSoup(page) #用BeautifulSoup解析网页
#找到具有class属性为下面两个的所有Tag
ALL = soup.findAll(attrs = {'class' : ['zm-item-title','zh-summary summary clearfix'] })
for each in ALL : #枚举所有的问题和回答
#print type(each.string)
#print each.name
if each.name == 'h2' : #如果Tag为h2类型,说明是问题
print each.a.string #问题中还有一个<a..>,所以要each.a.string取出内容
if each.a.string: #如果非空,才能写入
f.write(each.a.string)
else : #否则写"No Answer"
f.write("No Answer")
else : #如果是回答,同样写入
print each.string
if each.string:
f.write(each.string)
else :
f.write("No Answer")
f.close() #关闭文件代码虽然不长,可是写了我半天,开始各种出问题。
运行
然后我们运行就可以爬了:
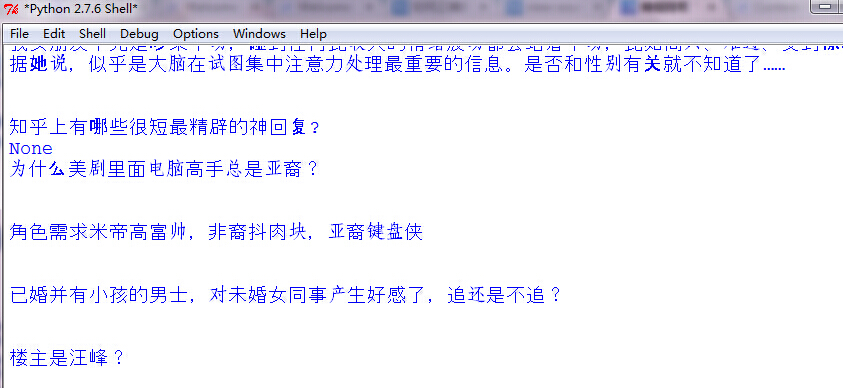 结果
结果
等运行完毕,我们打开文件howtoTucao.txt,可以看到,这样就爬取成功了。只是格式可能还是有点问题,原来是我No Answer没加换行,所以No Answer还会混到文本里面去,加两个换行就可以了。