用Python实现协同过滤的教程
协同过滤
在 用户 —— 物品(user - item)的数据关系下很容易收集到一些偏好信息(preference),比如评分。利用这些分散的偏好信息,基于其背后可能存在的关联性,来为用户推荐物品的方法,便是协同过滤,或称协作型过滤(collaborative filtering)。
这种过滤算法的有效性基础在于:
用户的偏好具有相似性,即用户是可分类的。这种分类的特征越明显,推荐的准确率就越高
物品之间是存在关系的,即偏好某一物品的任何人,都很可能也同时偏好另一件物品
不同环境下这两种理论的有效性也不同,应用时需做相应调整。如豆瓣上的文艺作品,用户对其的偏好程度与用户自身的品位关联性较强;而对于电子商务网站来说,商品之间的内在联系对用户的购买行为影响更为显著。当用在推荐上,这两种方向也被称为基于用户的和基于物品的。本文内容为基于用户的。
影评推荐实例
本文主要内容为基于用户偏好的相似性进行物品推荐,使用的数据集为 GroupLens Research 采集的一组从 20 世纪 90 年代末到 21 世纪初由 MovieLens 用户提供的电影评分数据。数据中包含了约 6000 名用户对约 4000 部电影的 100万条评分,五分制。数据包可以从网上下载到,里面包含了三个数据表——users、movies、ratings。因为本文的主题是基于用户偏好的,所以只使用 ratings 这一个文件。另两个文件里分别包含用户和电影的元信息。
本文使用的数据分析包为 pandas,环境为 IPython,因此其实还默认携带了 Numpy 和 matplotlib。下面代码中的提示符看起来不是 IPython 环境是因为 Idle 的格式发在博客上更好看一些。
数据规整
首先将评分数据从 ratings.dat 中读出到一个 DataFrame 里:
>>> import pandas as pd >>> from pandas import Series,DataFrame >>> rnames = ['user_id','movie_id','rating','timestamp'] >>> ratings = pd.read_table(r'ratings.dat',sep='::',header=None,names=rnames) >>> ratings[:3] user_id movie_id rating timestamp 0 1 1193 5 978300760 1 1 661 3 978302109 2 1 914 3 978301968 [3 rows x 4 columns]
ratings 表中对我们有用的仅是 user_id、movie_id 和 rating 这三列,因此我们将这三列取出,放到一个以 user 为行,movie 为列,rating 为值的表 data 里面。(其实将 user 与 movie 的行列关系对调是更加科学的方法,但因为重跑一遍太麻烦了,这里就没改。)
>>> data = ratings.pivot(index='user_id',columns='movie_id',values='rating') >>> data[:5] movie_id 1 2 3 4 5 6 user_id 1 5 NaN NaN NaN NaN NaN ... 2 NaN NaN NaN NaN NaN NaN ... 3 NaN NaN NaN NaN NaN NaN ... 4 NaN NaN NaN NaN NaN NaN ... 5 NaN NaN NaN NaN NaN 2 ...
可以看到这个表相当得稀疏,填充率大约只有 5%,接下来要实现推荐的第一步是计算 user 之间的相关系数,DataFrame 对象有一个很亲切的 .corr(method='pearson', min_periods=1) 方法,可以对所有列互相计算相关系数。method 默认为皮尔逊相关系数,这个 ok,我们就用这个。问题仅在于那个 min_periods 参数,这个参数的作用是设定计算相关系数时的最小样本量,低于此值的一对列将不进行运算。这个值的取舍关系到相关系数计算的准确性,因此有必要先来确定一下这个参数。
相关系数是用于评价两个变量间线性关系的一个值,取值范围为 [-1, 1],-1代表负相关,0 代表不相关,1 代表正相关。其中 0~0.1 一般被认为是弱相关,0.1~0.4 为相关,0.4~1 为强相关。
min_periods 参数测定
测定这样一个参数的基本方法为统计在 min_periods 取不同值时,相关系数的标准差大小,越小越好;但同时又要考虑到,我们的样本空间十分稀疏,min_periods 定得太高会导致出来的结果集太小,所以只能选定一个折中的值。
这里我们测定评分系统标准差的方法为:在 data 中挑选一对重叠评分最多的用户,用他们之间的相关系数的标准差去对整体标准差做点估计。在此前提下对这一对用户在不同样本量下的相关系数进行统计,观察其标准差变化。
首先,要找出重叠评分最多的一对用户。我们新建一个以 user 为行列的方阵 foo,然后挨个填充不同用户间重叠评分的个数:
>>> foo = DataFrame(np.empty((len(data.index),len(data.index)),dtype=int),index=data.index,columns=data.index) >>> for i in foo.index: for j in foo.columns: foo.ix[i,j] = data.ix[i][data.ix[j].notnull()].dropna().count()
这段代码特别费时间,因为最后一行语句要执行 4000*4000 = 1600万遍;(其中有一半是重复运算,因为 foo 这个方阵是对称的)还有一个原因是 Python 的 GIL,使得其只能使用一个 CPU 线程。我在它执行了一个小时后,忍不住去测试了一下总时间,发现要三个多小时后就果断 Ctrl + C 了,在算了一小半的 foo 中,我找到的最大值所对应的行列分别为 424 和 4169,这两位用户之间的重叠评分数为 998:
>>> for i in foo.index: foo.ix[i,i]=0#先把对角线的值设为 0 >>> ser = Series(np.zeros(len(foo.index))) >>> for i in foo.index: ser[i]=foo[i].max()#计算每行中的最大值 >>> ser.idxmax()#返回 ser 的最大值所在的行号 4169 >>> ser[4169]#取得最大值 998 >>> foo[foo==998][4169].dropna()#取得另一个 user_id 424 4169 Name: user_id, dtype: float64
我们把 424 和 4169 的评分数据单独拿出来,放到一个名为 test 的表里,另外计算了一下这两个用户之间的相关系数为 0.456,还算不错,另外通过柱状图了解一下他俩的评分分布情况:
>>> data.ix[4169].corr(data.ix[424]) 0.45663851303413217 >>> test = data.reindex([424,4169],columns=data.ix[4169][data.ix[424].notnull()].dropna().index) >>> test movie_id 2 6 10 11 12 17 ... 424 4 4 4 4 1 5 ... 4169 3 4 4 4 2 5 ... >>> test.ix[424].value_counts(sort=False).plot(kind='bar') >>> test.ix[4169].value_counts(sort=False).plot(kind='bar')
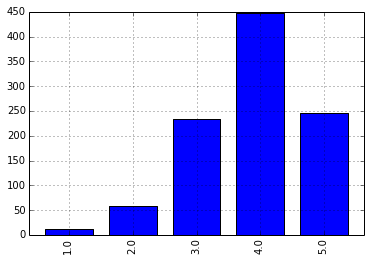
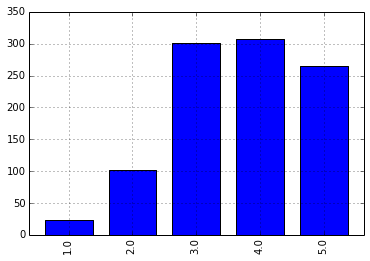
对这俩用户的相关系数统计,我们分别随机抽取 20、50、100、200、500 和 998 个样本值,各抽 20 次。并统计结果:
>>> periods_test = DataFrame(np.zeros((20,7)),columns=[10,20,50,100,200,500,998])
>>> for i in periods_test.index:
for j in periods_test.columns:
sample = test.reindex(columns=np.random.permutation(test.columns)[:j])
periods_test.ix[i,j] = sample.iloc[0].corr(sample.iloc[1])
>>> periods_test[:5]
10 20 50 100 200 500 998
0 -0.306719 0.709073 0.504374 0.376921 0.477140 0.426938 0.456639
1 0.386658 0.607569 0.434761 0.471930 0.437222 0.430765 0.456639
2 0.507415 0.585808 0.440619 0.634782 0.490574 0.436799 0.456639
3 0.628112 0.628281 0.452331 0.380073 0.472045 0.444222 0.456639
4 0.792533 0.641503 0.444989 0.499253 0.426420 0.441292 0.456639
[5 rows x 7 columns]
>>> periods_test.describe()
10 20 50 100 200 500 #998略
count 20.000000 20.000000 20.000000 20.000000 20.000000 20.000000
mean 0.346810 0.464726 0.458866 0.450155 0.467559 0.452448
std 0.398553 0.181743 0.103820 0.093663 0.036439 0.029758
min -0.444302 0.087370 0.192391 0.242112 0.412291 0.399875
25% 0.174531 0.320941 0.434744 0.375643 0.439228 0.435290
50% 0.487157 0.525217 0.476653 0.468850 0.472562 0.443772
75% 0.638685 0.616643 0.519827 0.500825 0.487389 0.465787
max 0.850963 0.709073 0.592040 0.634782 0.546001 0.513486
[8 rows x 7 columns]
从 std 这一行来看,理想的 min_periods 参数值应当为 200 左右。可能有人会觉得 200 太大了,这个推荐算法对新用户简直没意义。但是得说,随便算出个有超大误差的相关系数,然后拿去做不靠谱的推荐,又有什么意义呢。
算法检验
为了确认在 min_periods=200 下本推荐算法的靠谱程度,最好还是先做个检验。具体方法为:在评价数大于 200 的用户中随机抽取 1000 位用户,每人随机提取一个评价另存到一个数组里,并在数据表中删除这个评价。然后基于阉割过的数据表计算被提取出的 1000 个评分的期望值,最后与真实评价数组进行相关性比较,看结果如何。
>>> check_size = 1000
>>> check = {}
>>> check_data = data.copy()#复制一份 data 用于检验,以免篡改原数据
>>> check_data = check_data.ix[check_data.count(axis=1)>200]#滤除评价数小于200的用户
>>> for user in np.random.permutation(check_data.index):
movie = np.random.permutation(check_data.ix[user].dropna().index)[0]
check[(user,movie)] = check_data.ix[user,movie]
check_data.ix[user,movie] = np.nan
check_size -= 1
if not check_size:
break
>>> corr = check_data.T.corr(min_periods=200)
>>> corr_clean = corr.dropna(how='all')
>>> corr_clean = corr_clean.dropna(axis=1,how='all')#删除全空的行和列
>>> check_ser = Series(check)#这里是被提取出来的 1000 个真实评分
>>> check_ser[:5]
(15, 593) 4
(23, 555) 3
(33, 3363) 4
(36, 2355) 5
(53, 3605) 4
dtype: float64
接下来要基于 corr_clean 给 check_ser 中的 1000 个 用户-影片 对计算评分期望。计算方法为:对与用户相关系数大于 0.1 的其他用户评分进行加权平均,权值为相关系数:
>>> result = Series(np.nan,index=check_ser.index)
>>> for user,movie in result.index:#这个循环看着很乱,实际内容就是加权平均而已
prediction = []
if user in corr_clean.index:
corr_set = corr_clean[user][corr_clean[user]>0.1].dropna()#仅限大于 0.1 的用户
else:continue
for other in corr_set.index:
if not np.isnan(data.ix[other,movie]) and other != user:#注意bool(np.nan)==True
prediction.append((data.ix[other,movie],corr_set[other]))
if prediction:
result[(user,movie)] = sum([value*weight for value,weight in prediction])/sum([pair[1] for pair in prediction])
>>> result.dropna(inplace=True)
>>> len(result)#随机抽取的 1000 个用户中也有被 min_periods=200 刷掉的
862
>>> result[:5]
(23, 555) 3.967617
(33, 3363) 4.073205
(36, 2355) 3.903497
(53, 3605) 2.948003
(62, 1488) 2.606582
dtype: float64
>>> result.corr(check_ser.reindex(result.index))
0.436227437429696
>>> (result-check_ser.reindex(result.index)).abs().describe()#推荐期望与实际评价之差的绝对值
count 862.000000
mean 0.785337
std 0.605865
min 0.000000
25% 0.290384
50% 0.686033
75% 1.132256
max 3.629720
dtype: float64
862 的样本量能达到 0.436 的相关系数,应该说结果还不错。如果一开始没有滤掉评价数小于 200 的用户的话,那么首先在计算 corr 时会明显感觉时间变长,其次 result 中的样本量会很小,大约 200+ 个。但因为样本量变小的缘故,相关系数可以提升到 0.5~0.6 。
另外从期望与实际评价的差的绝对值的统计量上看,数据也比较理想。
实现推荐
在上面的检验,尤其是平均加权的部分做完后,推荐的实现就没有什么新东西了。
首先在原始未阉割的 data 数据上重做一份 corr 表:
>>> corr = data.T.corr(min_periods=200) >>> corr_clean = corr.dropna(how='all') >>> corr_clean = corr_clean.dropna(axis=1,how='all')
我们在 corr_clean 中随机挑选一位用户为他做一个推荐列表:
>>> lucky = np.random.permutation(corr_clean.index)[0] >>> gift = data.ix[lucky] >>> gift = gift[gift.isnull()]#现在 gift 是一个全空的序列
最后的任务就是填充这个 gift:
>>> corr_lucky = corr_clean[lucky].drop(lucky)#lucky 与其他用户的相关系数 Series,不包含 lucky 自身
>>> corr_lucky = corr_lucky[corr_lucky>0.1].dropna()#筛选相关系数大于 0.1 的用户
>>> for movie in gift.index:#遍历所有 lucky 没看过的电影
prediction = []
for other in corr_lucky.index:#遍历所有与 lucky 相关系数大于 0.1 的用户
if not np.isnan(data.ix[other,movie]):
prediction.append((data.ix[other,movie],corr_clean[lucky][other]))
if prediction:
gift[movie] = sum([value*weight for value,weight in prediction])/sum([pair[1] for pair in prediction])
>>> gift.dropna().order(ascending=False)#将 gift 的非空元素按降序排列
movie_id
3245 5.000000
2930 5.000000
2830 5.000000
2569 5.000000
1795 5.000000
981 5.000000
696 5.000000
682 5.000000
666 5.000000
572 5.000000
1420 5.000000
3338 4.845331
669 4.660464
214 4.655798
3410 4.624088
...
2833 1
2777 1
2039 1
1773 1
1720 1
1692 1
1538 1
1430 1
1311 1
1164 1
843 1
660 1
634 1
591 1
56 1
Name: 3945, Length: 2991, dtype: float64
补充
上面给出的示例都是些原型代码,有很多可优化的空间。比如 data 的行列转换;比如测定 min_periods 时的方阵 foo 只需计算一半;比如有些 for 循环和相应运算可以用数组对象方法来实现(方法版比用户自己编写的版本速度快很多);甚至肯定还有一些 bug。另外这个数据集的体积还不算太大,如果再增长一个数量级,那么就有必要针对计算密集的部分(如 corr)做进一步优化了,可以使用多进程,或者 Cython/C 代码。(或者换更好的硬件)
虽然协同过滤是一种比较省事的推荐方法,但在某些场合下并不如利用元信息推荐好用。协同过滤会遇到的两个常见问题是
- 稀疏性问题——因用户做出评价过少,导致算出的相关系数不准确
- 冷启动问题——因物品获得评价过少,导致无“权”进入推荐列表中
都是样本量太少导致的。(上例中也使用了至少 200 的有效重叠评价数)因此在对于新用户和新物品进行推荐时,使用一些更一般性的方法效果可能会更好。比如给新用户推荐更多平均得分超高的电影;把新电影推荐给喜欢类似电影(如具有相同导演或演员)的人。后面这种做法需要维护一个物品分类表,这个表既可以是基于物品元信息划分的,也可是通过聚类得到的。