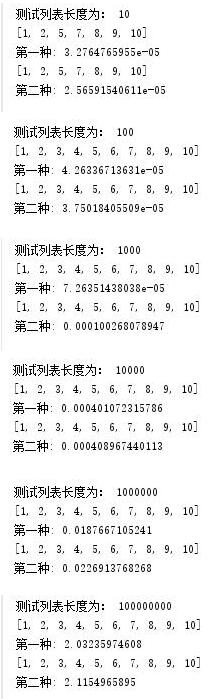
Python的ORM框架中SQLAlchemy库的查询操作的教程
1. 返回列表和标量(Scalar)
前面我们注意到Query对象可以返回可迭代的值(iterator value),然后我们可以通过for in来查询。不过Query对象的all()、one()以及first()方法将返回非迭代值(non-iterator value),比如说all()返回的是一个列表:
>>> query = session.query(User).\
>>> filter(User.name.like('%ed')).order_by(User.id)
>>> query.all()
SELECT users.id AS users_id,
users.name AS users_name,
users.fullname AS users_fullname,
users.password AS users_password
FROM users
WHERE users.name LIKE ? ORDER BY users.id
('%ed',)
[User('ed','Ed Jones', 'f8s7ccs'), User('fred','Fred Flinstone', 'blah')]
first()方法限制并仅作为标量返回结果集的第一条记录:
>>> query.first()
SELECT users.id AS users_id,
users.name AS users_name,
users.fullname AS users_fullname,
users.password AS users_password
FROM users
WHERE users.name LIKE ? ORDER BY users.id
LIMIT ? OFFSET ?
('%ed', 1, 0)
<User('ed','Ed Jones', 'f8s7ccs')>
one()方法,完整的提取所有的记录行,并且如果没有明确的一条记录行(没有找到这条记录)或者结果中存在多条记录行,将会引发错误异常NoResultFound或者MultipleResultsFound:
>>> from sqlalchemy.orm.exc import MultipleResultsFound
>>> try:
... user = query.one()
... except MultipleResultsFound, e:
... print e
SELECT users.id AS users_id,
users.name AS users_name,
users.fullname AS users_fullname,
users.password AS users_password
FROM users
WHERE users.name LIKE ? ORDER BY users.id
('%ed',)
Multiple rows were found for one()
>>> from sqlalchemy.orm.exc import NoResultFound
>>> try:
... user = query.filter(User.id == 99).one()
... except NoResultFound, e:
... print e
SELECT users.id AS users_id,
users.name AS users_name,
users.fullname AS users_fullname,
users.password AS users_password
FROM users
WHERE users.name LIKE ? AND users.id = ? ORDER BY users.id
('%ed', 99)
No row was found for one()
2. 使用原义SQL (Literal SQL)
Query对象能够灵活的使用原义SQL查询字符串作为查询参数,比如我们之前用过的filter()和order_by()方法:
>>> for user in session.query(User).\
... filter("id<224").\
... order_by("id").all():
... print user.name
SELECT users.id AS users_id,
users.name AS users_name,
users.fullname AS users_fullname,
users.password AS users_password
FROM users
WHERE id<224 ORDER BY id
()
ed
wendy
mary
fred
当然很多人可能会和我感觉一样,会有些不适应,因为使用ORM就是为了摆脱SQL语句的,没想到现在又看到SQL的影子了。呵呵,SQLAlchemy也要照顾到使用上的灵活性嘛,毕竟有些查询语句直接编入要容易得多。
当然绑定参数也可以用基于字符串的SQL指派,使用冒号来标记替代参数,然后再使用params()方法指定相应的值:
>>> session.query(User).filter("id<:value and name=:name").\
... params(value=224, name='fred').order_by(User.id).one()
SELECT users.id AS users_id,
users.name AS users_name,
users.fullname AS users_fullname,
users.password AS users_password
FROM users
WHERE id<User('fred','Fred Flinstone', 'blah')>
到这里,SQL语句的样子已经初见端倪了,其实我们可以更极端一点,直接使用SQL语句,什么?这样就失去ORM的价值了!别急,这里只是介绍一下支持这种用法,当然我建议不到万不得已,尽量不要这样写,因为可能会有兼容的问题,毕竟各个数据库的SQL方言不一样。不过有一点需要注意的是,如果要直接使用原生SQL语句,在被query()所查询的映射类中,你必须保证语句所指代的列仍然被映射类所管理,比如接下来的例子:
>>> session.query(User).from_statement(
... "SELECT * FROM users where name=:name").\
... params(name='ed').all()
SELECT * FROM users where name=?
('ed',)
[<User('ed','Ed Jones', 'f8s7ccs')>]
我们还可以在query()中直接使用列名来指派我们想要的列而摆脱映射类的束缚:
>>> session.query("id", "name", "thenumber12").\
... from_statement("SELECT id, name, 12 as "
... "thenumber12 FROM users where name=:name").\
... params(name='ed').all()
SELECT id, name, 12 as thenumber12 FROM users where name=?
('ed',)
[(1, u'ed', 12)]
3. 计数 (Counting)
对于Query来说,计数功能也有个单独的方法称为count():
>>> session.query(User).filter(User.name.like('%ed')).count()
SELECT count(*) AS count_1
FROM (SELECT users.id AS users_id,
users.name AS users_name,
users.fullname AS users_fullname,
users.password AS users_password
FROM users
WHERE users.name LIKE ?) AS anon_1
('%ed',)
2
count()方法被用于确定返回的结果集中有多少行,让我们观察一下产生的SQL语句,SQLAlchemy先是取出符合条件的所有行集合,然后再通过SELECT count(*)来统计有多少行。当然有点SQL知识的同学可能知道这条语句可以以更精简的方式写出来,比如SELECT count(*) FROM table,当然现代版本的SQLAlchemy不会去揣摩这样的想法。
假使我们要让查询语句更加精炼或者要明确要统计的列,我们可以通过表达式func.count()直接使用count函数,比如下面的例子介绍统计并返回每个唯一的用户名字:
>>> from sqlalchemy import func >>> session.query(func.count(User.name), User.name).group_by(User.name).all() SELECT count(users.name) AS count_1, users.name AS users_name FROM users GROUP BY users.name () [(1, u'ed'), (1, u'fred'), (1, u'mary'), (1, u'wendy')]
对于刚才提到的简单SELECT count(*) FROM table语句,我们可以通过下面的例子来实现:
>>> session.query(func.count('*')).select_from(User).scalar()
SELECT count(?) AS count_1
FROM users
('*',)
4
当然如果我们直接统计User的主键,上面的语句可以更加简练,我们可以省去select_from()方法:
>>> session.query(func.count(User.id)).scalar() SELECT count(users.id) AS count_1 FROM users () 4