Python3.5 Pandas模块之DataFrame用法实例分析
本文实例讲述了Python3.5 Pandas模块之DataFrame用法。分享给大家供大家参考,具体如下:
1、DataFrame的创建
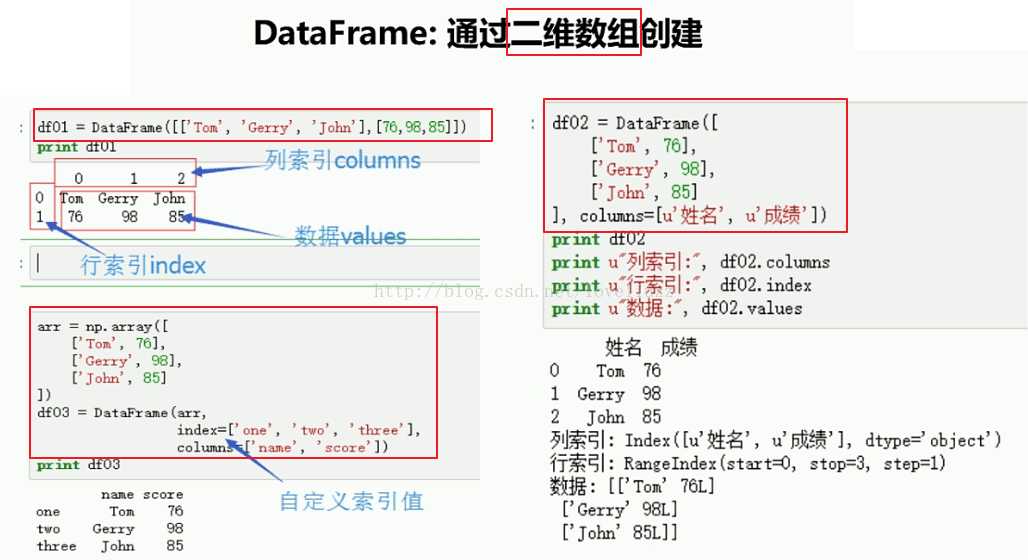
(1)通过二维数组方式创建
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:ZhengzhengLiu
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
#1.DataFrame通过二维数组创建
print("======DataFrame直接通过二维数组创建======")
d1 = DataFrame([["a","b","c","d"],[1,2,3,4]])
print(d1)
print("======DataFrame借助array二维数组创建======")
arr = np.array([
["jack",78],
["lili",86],
["amy",97],
["tom",100]
])
d2 = DataFrame(arr,index=["01","02","03","04"],columns=["姓名","成绩"])
print(d2)
print("========打印行索引========")
print(d2.index)
print("========打印列索引========")
print(d2.columns)
print("========打印值========")
print(d2.values)
运行结果:
======DataFrame直接通过二维数组创建======
0 1 2 3
0 a b c d
1 1 2 3 4
======DataFrame借助array二维数组创建======
姓名 成绩
01 jack 78
02 lili 86
03 amy 97
04 tom 100
========打印行索引========
Index(['01', '02', '03', '04'], dtype='object')
========打印列索引========
Index(['姓名', '成绩'], dtype='object')
========打印值========
[['jack' '78']
['lili' '86']
['amy' '97']
['tom' '100']]
(2)通过字典方式创建
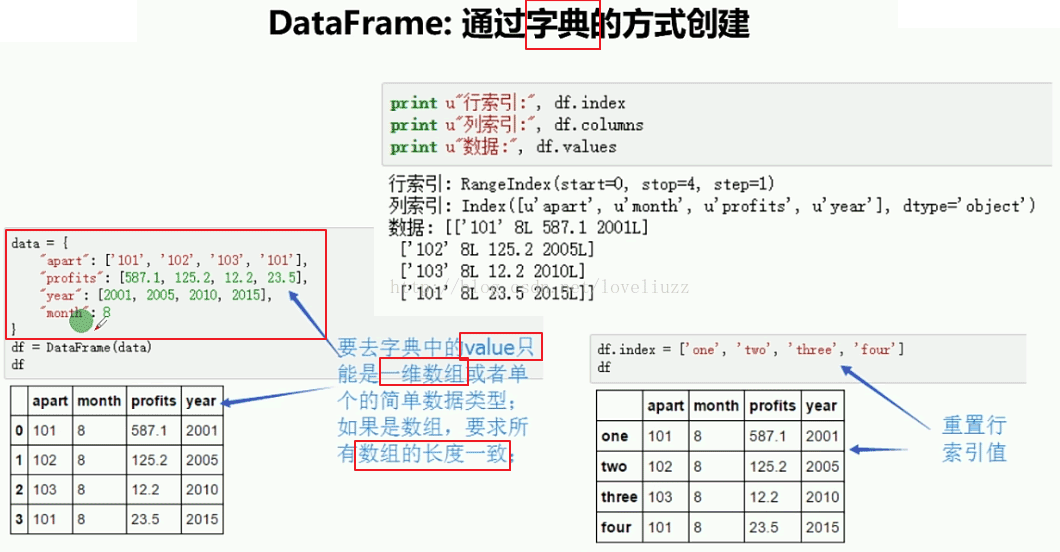
#2.DataFrame通过字典创建,键作为列索引,键值作为数据值,行索引值自动生成
data = {
"apart":['1101',"1102","1103","1104"],
"profit":[2000,4000,5000,3500],
"month":8
}
d3 = DataFrame(data)
print(d3)
print("========行索引========")
print(d3.index)
print("========列索引========")
print(d3.columns)
print("========数据值========")
print(d3.values)
运行结果:
apart month profit
0 1101 8 2000
1 1102 8 4000
2 1103 8 5000
3 1104 8 3500
========行索引========
RangeIndex(start=0, stop=4, step=1)
========列索引========
Index(['apart', 'month', 'profit'], dtype='object')
========数据值========
[['1101' 8 2000]
['1102' 8 4000]
['1103' 8 5000]
['1104' 8 3500]]
2、DataFrame数据获取


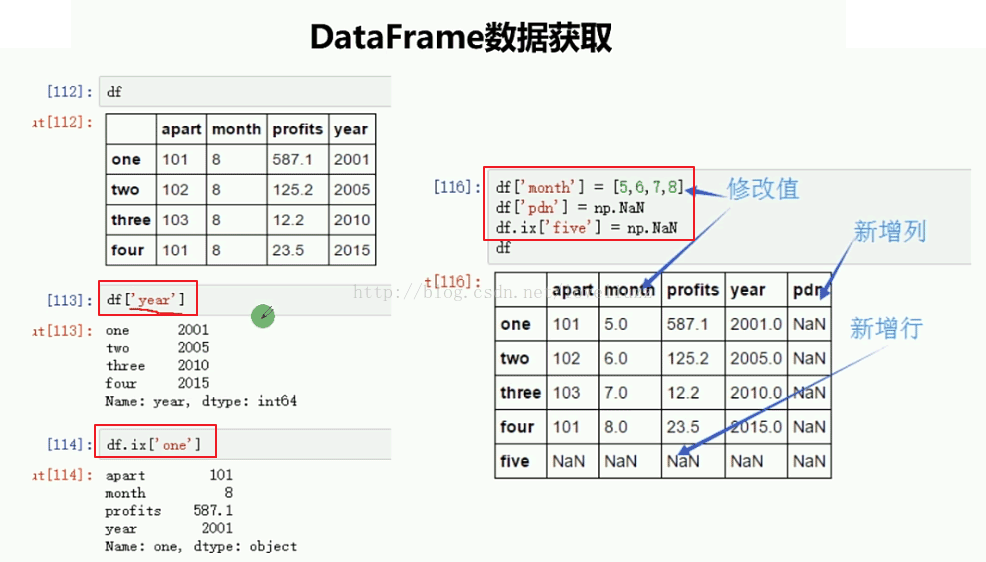
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
#3.DataFrame获取数据
data = {
"apart":['1101',"1102","1103","1104"],
"profit":[2000,4000,5000,3500],
"month":8
}
d3 = DataFrame(data)
print(d3)
print("======获取一列数据======")
print(d3["apart"])
print("======获取一行数据======")
print(d3.ix[1])
print("======修改数据值======")
d3["month"] = [7,8,9,10] #修改值
d3["year"] = [2001,2001,2003,2004] #新增列
d3.ix["4"] = np.NaN
print(d3)
运行结果:
apart month profit
0 1101 8 2000
1 1102 8 4000
2 1103 8 5000
3 1104 8 3500
======获取一列数据======
0 1101
1 1102
2 1103
3 1104
Name: apart, dtype: object
======获取一行数据======
apart 1102
month 8
profit 4000
Name: 1, dtype: object
======修改数据值======
apart month profit year
0 1101 7.0 2000.0 2001.0
1 1102 8.0 4000.0 2001.0
2 1103 9.0 5000.0 2003.0
3 1104 10.0 3500.0 2004.0
4 NaN NaN NaN NaN
3、pandas基本功能

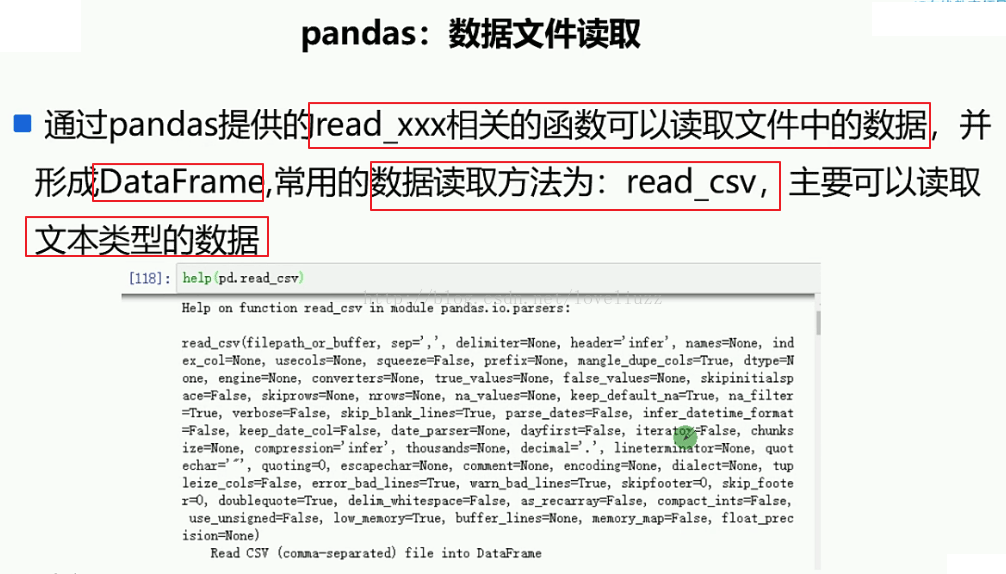
(1)pandas数据文件读取
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
#pandas基本操作
#1.数据文件读取
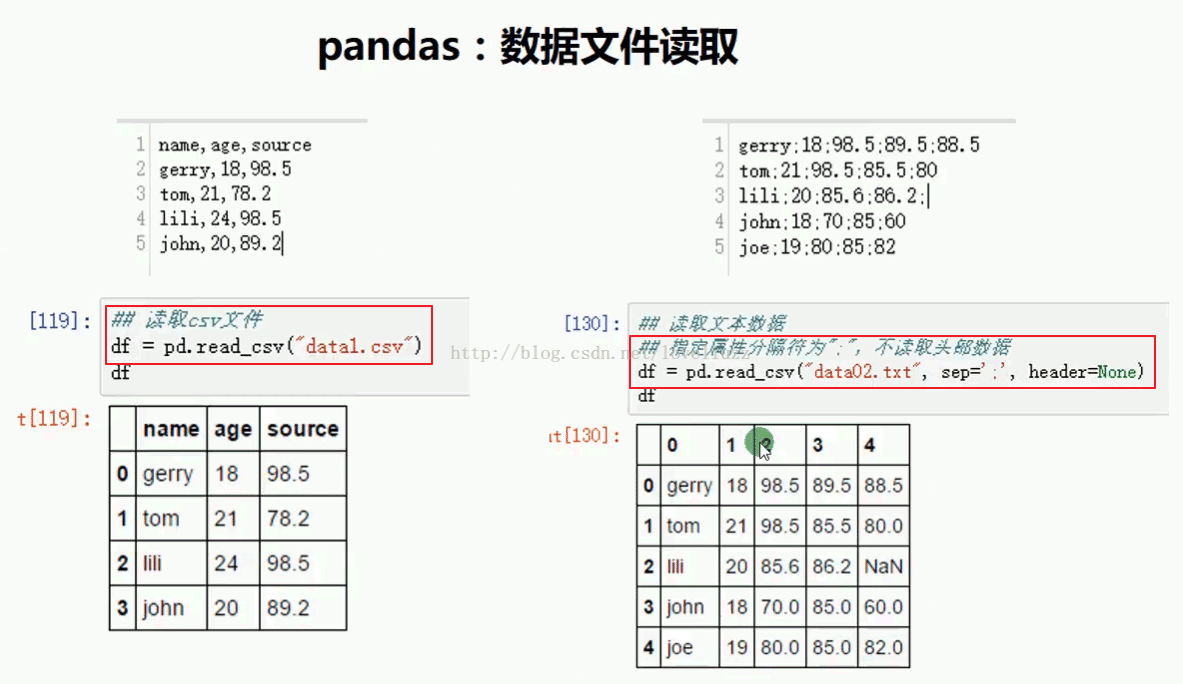
df = pd.read_csv("data.csv")
print(df)
运行结果:
name age source
0 gerry 18 98.5
1 tom 21 78.2
2 lili 24 98.5
3 john 20 89.2
(2)数据过滤获取
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
#pandas基本操作
#1.数据文件读取
df = pd.read_csv("data.csv")
print(df)
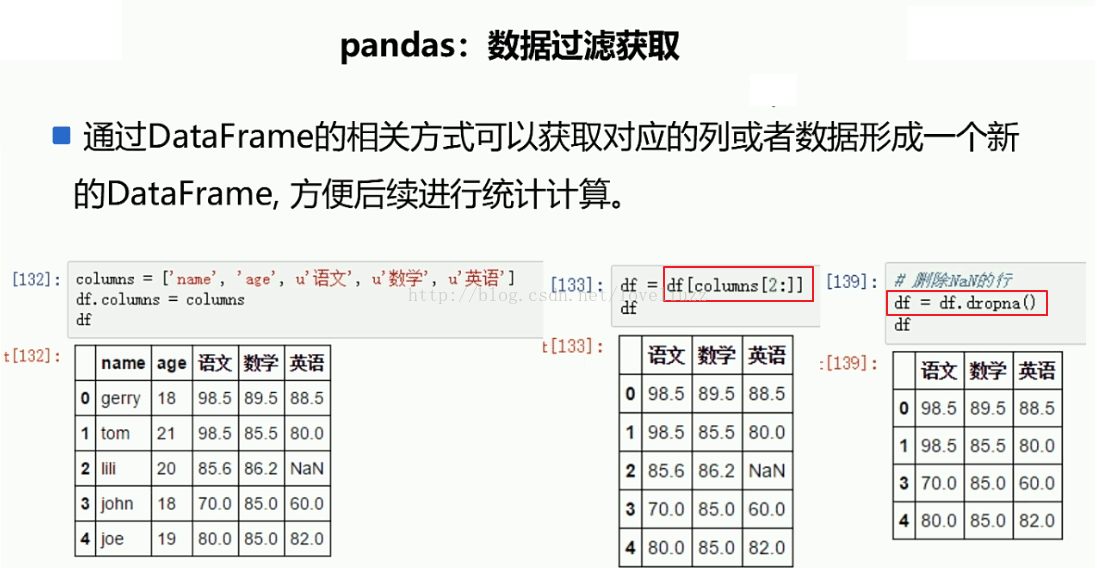
#2.数据过滤获取
columns = ["姓名","年龄","成绩"]
df.columns = columns #更改列索引
print("=======更改列索引========")
print(df)
#获取几列的值
df1 = df[columns[1:]]
print("=======获取几列的值========")
print(df1)
print("=======获取几行的值========")
print(df.ix[1:3])
#删除含有NaN值的行
df2 = df1.dropna()
print("=======删除含有NaN值的行=======")
print(df2)
运行结果:
name age source
0 gerry 18 98.5
1 tom 21 NaN
2 lili 24 98.5
3 john 20 89.2
=======更改列索引========
姓名 年龄 成绩
0 gerry 18 98.5
1 tom 21 NaN
2 lili 24 98.5
3 john 20 89.2
=======获取几列的值========
年龄 成绩
0 18 98.5
1 21 NaN
2 24 98.5
3 20 89.2
=======获取几行的值========
姓名 年龄 成绩
1 tom 21 NaN
2 lili 24 98.5
3 john 20 89.2
=======删除含有NaN值的行=======
年龄 成绩
0 18 98.5
2 24 98.5
3 20 89.2
更多关于Python相关内容感兴趣的读者可查看本站专题:《Python数学运算技巧总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。