使用Python编写简单的端口扫描器的实例分享
单线程实现
单线程实现道理比较简单,这里尝试Soket连接3389,连接成功说明端口开放,否则说明没有开远程服务。随便修改了一下就ok了,代码如下,最终得到自己的IP地址。
#!/usr/bin/env python
import socket
if __name__=='__main__':
port=3389
s=socket.socket()
for cnt in range(253,2,-1):
address='XXX.XXX.XXX.'+str(cnt) #XXX.XXX.XXX IP网段
try:
s.connect((address,port))
print address
except socket.error,e:
print 'Error OR Port Not Opened'
Python的代码简单明了,但是功能不简单,速度有些慢,主要还是单线程和网络的原因吧。改进一下可以当一个简陋的端口扫描器使用了,扫描指定网段、指定端口,多线程速度可能能好一点吧。
多线程实现
前几天看了个讲使用Python扫描端口的教程,看了之后自己也写了个扫描端口的脚本。记录下来,方便自己以后回顾。
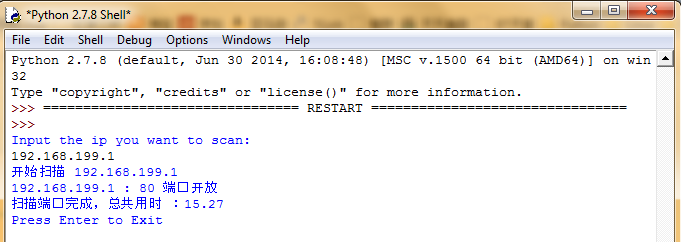
端口扫描端口效果图
python扫描器源代码
# -*- coding:utf8 -*-
#!/usr/bin/python
# Python: 2.7.8
# Platform: Windows
# Authro: wucl
# Program: 端口扫描
# History: 2015.6.1
import socket, time, thread
socket.setdefaulttimeout(3)
def socket_port(ip,port):
"""
输入IP和端口号,扫描判断端口是否开放
"""
try:
if port>=65535:
print u'端口扫描结束'
s=socket.socket(socket.AF_INET, socket.SOCK_STREAM)
result=s.connect_ex((ip,port))
if result==0:
lock.acquire()
print ip,u':',port,u'端口开放'
lock.release()
s.close()
except:
print u'端口扫描异常'
def ip_scan(ip):
"""
输入IP,扫描IP的0-65534端口情况
"""
try:
print u'开始扫描 %s' % ip
start_time=time.time()
for i in range(0,65534):
thread.start_new_thread(socket_port,(ip,int(i)))
print u'扫描端口完成,总共用时 :%.2f' %(time.time()-start_time)
raw_input("Press Enter to Exit")
except:
print u'扫描ip出错'
if __name__=='__main__':
url=raw_input('Input the ip you want to scan:\n')
lock=thread.allocate_lock()
ip_scan(url)