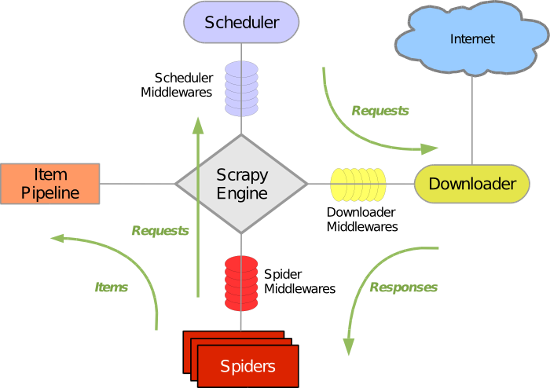
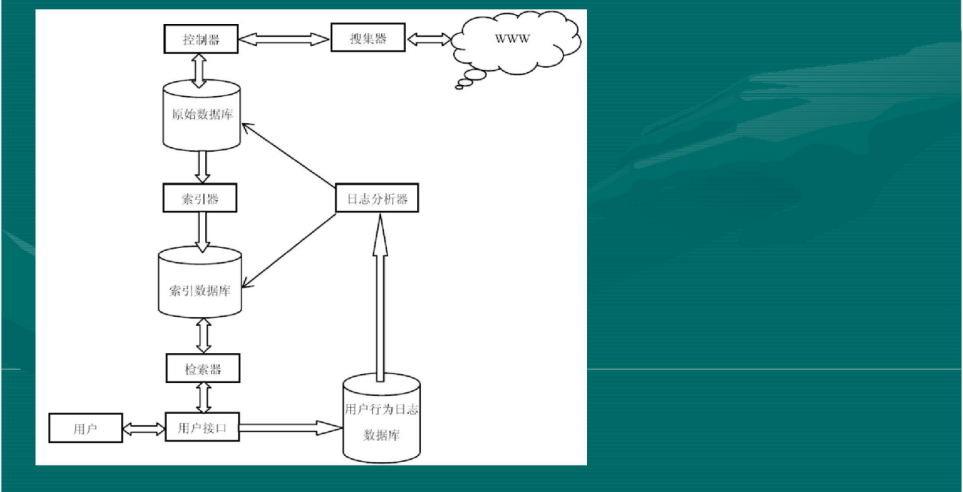
Python多线程、异步+多进程爬虫实现代码
安装Tornado
省事点可以直接用grequests库,下面用的是tornado的异步client。 异步用到了tornado,根据官方文档的例子修改得到一个简单的异步爬虫类。可以参考下最新的文档学习下。
pip install tornado
异步爬虫
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import time
from datetime import timedelta
from tornado import httpclient, gen, ioloop, queues
import traceback
class AsySpider(object):
"""A simple class of asynchronous spider."""
def __init__(self, urls, concurrency=10, **kwargs):
urls.reverse()
self.urls = urls
self.concurrency = concurrency
self._q = queues.Queue()
self._fetching = set()
self._fetched = set()
def fetch(self, url, **kwargs):
fetch = getattr(httpclient.AsyncHTTPClient(), 'fetch')
return fetch(url, **kwargs)
def handle_html(self, url, html):
"""handle html page"""
print(url)
def handle_response(self, url, response):
"""inherit and rewrite this method"""
if response.code == 200:
self.handle_html(url, response.body)
elif response.code == 599: # retry
self._fetching.remove(url)
self._q.put(url)
@gen.coroutine
def get_page(self, url):
try:
response = yield self.fetch(url)
print('######fetched %s' % url)
except Exception as e:
print('Exception: %s %s' % (e, url))
raise gen.Return(e)
raise gen.Return(response)
@gen.coroutine
def _run(self):
@gen.coroutine
def fetch_url():
current_url = yield self._q.get()
try:
if current_url in self._fetching:
return
print('fetching****** %s' % current_url)
self._fetching.add(current_url)
response = yield self.get_page(current_url)
self.handle_response(current_url, response) # handle reponse
self._fetched.add(current_url)
for i in range(self.concurrency):
if self.urls:
yield self._q.put(self.urls.pop())
finally:
self._q.task_done()
@gen.coroutine
def worker():
while True:
yield fetch_url()
self._q.put(self.urls.pop()) # add first url
# Start workers, then wait for the work queue to be empty.
for _ in range(self.concurrency):
worker()
yield self._q.join(timeout=timedelta(seconds=300000))
assert self._fetching == self._fetched
def run(self):
io_loop = ioloop.IOLoop.current()
io_loop.run_sync(self._run)
class MySpider(AsySpider):
def fetch(self, url, **kwargs):
"""重写父类fetch方法可以添加cookies,headers,timeout等信息"""
cookies_str = "PHPSESSID=j1tt66a829idnms56ppb70jri4; pspt=%7B%22id%22%3A%2233153%22%2C%22pswd%22%3A%228835d2c1351d221b4ab016fbf9e8253f%22%2C%22_code%22%3A%22f779dcd011f4e2581c716d1e1b945861%22%7D; key=%E9%87%8D%E5%BA%86%E5%95%84%E6%9C%A8%E9%B8%9F%E7%BD%91%E7%BB%9C%E7%A7%91%E6%8A%80%E6%9C%89%E9%99%90%E5%85%AC%E5%8F%B8; think_language=zh-cn; SERVERID=a66d7d08fa1c8b2e37dbdc6ffff82d9e|1444973193|1444967835; CNZZDATA1254842228=1433864393-1442810831-%7C1444972138" # 从浏览器拷贝cookie字符串
headers = {
'User-Agent': 'mozilla/5.0 (compatible; baiduspider/2.0; +http://www.baidu.com/search/spider.html)',
'cookie': cookies_str
}
return super(MySpider, self).fetch( # 参数参考tornado文档
url, headers=headers, request_timeout=1
)
def handle_html(self, url, html):
print(url, html)
def main():
urls = []
for page in range(1, 100):
urls.append('http://www.baidu.com?page=%s' % page)
s = MySpider(urls)
s.run()
if __name__ == '__main__':
main()
可以继承这个类,塞一些url进去,然后重写handle_page处理得到的页面。
异步+多进程爬虫
还可以再变态点,加个进程池,使用了multiprocessing模块。效率飕飕的,
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import time
from multiprocessing import Pool
from datetime import timedelta
from tornado import httpclient, gen, ioloop, queues
class AsySpider(object):
"""A simple class of asynchronous spider."""
def __init__(self, urls, concurrency):
urls.reverse()
self.urls = urls
self.concurrency = concurrency
self._q = queues.Queue()
self._fetching = set()
self._fetched = set()
def handle_page(self, url, html):
filename = url.rsplit('/', 1)[1]
with open(filename, 'w+') as f:
f.write(html)
@gen.coroutine
def get_page(self, url):
try:
response = yield httpclient.AsyncHTTPClient().fetch(url)
print('######fetched %s' % url)
except Exception as e:
print('Exception: %s %s' % (e, url))
raise gen.Return('')
raise gen.Return(response.body)
@gen.coroutine
def _run(self):
@gen.coroutine
def fetch_url():
current_url = yield self._q.get()
try:
if current_url in self._fetching:
return
print('fetching****** %s' % current_url)
self._fetching.add(current_url)
html = yield self.get_page(current_url)
self._fetched.add(current_url)
self.handle_page(current_url, html)
for i in range(self.concurrency):
if self.urls:
yield self._q.put(self.urls.pop())
finally:
self._q.task_done()
@gen.coroutine
def worker():
while True:
yield fetch_url()
self._q.put(self.urls.pop())
# Start workers, then wait for the work queue to be empty.
for _ in range(self.concurrency):
worker()
yield self._q.join(timeout=timedelta(seconds=300000))
assert self._fetching == self._fetched
def run(self):
io_loop = ioloop.IOLoop.current()
io_loop.run_sync(self._run)
def run_spider(beg, end):
urls = []
for page in range(beg, end):
urls.append('http://127.0.0.1/%s.htm' % page)
s = AsySpider(urls, 10)
s.run()
def main():
_st = time.time()
p = Pool()
all_num = 73000
num = 4 # number of cpu cores
per_num, left = divmod(all_num, num)
s = range(0, all_num, per_num)
res = []
for i in range(len(s)-1):
res.append((s[i], s[i+1]))
res.append((s[len(s)-1], all_num))
print res
for i in res:
p.apply_async(run_spider, args=(i[0], i[1],))
p.close()
p.join()
print time.time()-_st
if __name__ == '__main__':
main()
多线程爬虫
线程池实现.
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import Queue
import sys
import requests
import os
import threading
import time
class Worker(threading.Thread): # 处理工作请求
def __init__(self, workQueue, resultQueue, **kwds):
threading.Thread.__init__(self, **kwds)
self.setDaemon(True)
self.workQueue = workQueue
self.resultQueue = resultQueue
def run(self):
while 1:
try:
callable, args, kwds = self.workQueue.get(False) # get task
res = callable(*args, **kwds)
self.resultQueue.put(res) # put result
except Queue.Empty:
break
class WorkManager: # 线程池管理,创建
def __init__(self, num_of_workers=10):
self.workQueue = Queue.Queue() # 请求队列
self.resultQueue = Queue.Queue() # 输出结果的队列
self.workers = []
self._recruitThreads(num_of_workers)
def _recruitThreads(self, num_of_workers):
for i in range(num_of_workers):
worker = Worker(self.workQueue, self.resultQueue) # 创建工作线程
self.workers.append(worker) # 加入到线程队列
def start(self):
for w in self.workers:
w.start()
def wait_for_complete(self):
while len(self.workers):
worker = self.workers.pop() # 从池中取出一个线程处理请求
worker.join()
if worker.isAlive() and not self.workQueue.empty():
self.workers.append(worker) # 重新加入线程池中
print 'All jobs were complete.'
def add_job(self, callable, *args, **kwds):
self.workQueue.put((callable, args, kwds)) # 向工作队列中加入请求
def get_result(self, *args, **kwds):
return self.resultQueue.get(*args, **kwds)
def download_file(url):
#print 'beg download', url
requests.get(url).text
def main():
try:
num_of_threads = int(sys.argv[1])
except:
num_of_threads = 10
_st = time.time()
wm = WorkManager(num_of_threads)
print num_of_threads
urls = ['http://www.baidu.com'] * 1000
for i in urls:
wm.add_job(download_file, i)
wm.start()
wm.wait_for_complete()
print time.time() - _st
if __name__ == '__main__':
main()
这三种随便一种都有很高的效率,但是这么跑会给网站服务器不小的压力,尤其是小站点,还是有点节操为好。