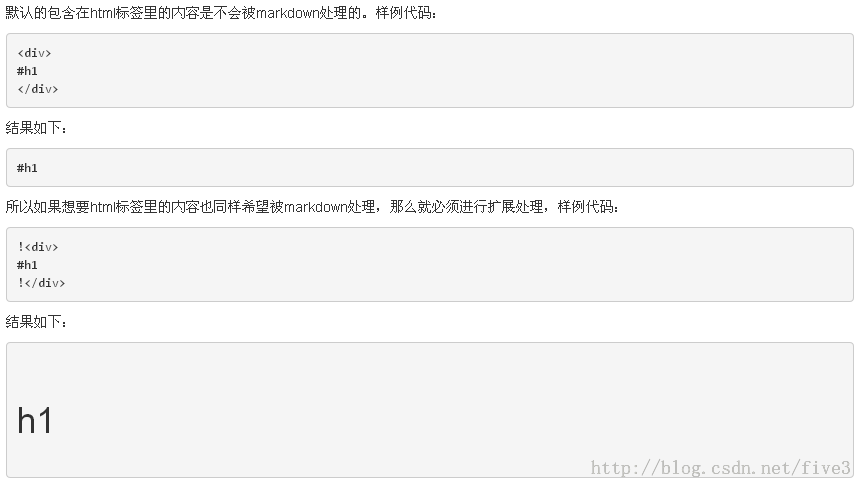
使用Python来开发Markdown脚本扩展的实例分享
关于Markdown
在刚才的导语里提到,Markdown 是一种用来写作的轻量级「标记语言」,它用简洁的语法代替排版,而不像一般我们用的字处理软件 Word 或 Pages 有大量的排版、字体设置。它使我们专心于码字,用「标记」语法,来代替常见的排版格式。例如此文从内容到格式,甚至插图,键盘就可以通通搞定了。目前来看,支持 Markdown 语法的编辑器有很多,包括很多网站(例如简书)也支持了 Markdown 的文字录入。Markdown 从写作到完成,导出格式随心所欲,你可以导出 HTML 格式的文件用来网站发布,也可以十分方便的导出 PDF 格式,这种格式写出的简历更能得到 HR 的好感。甚至可以利用 CloudApp 这种云服务工具直接上传至网页用来分享你的文章,全球最大的轻博客平台 Tumblr,也支持使用 Mou 这类 Markdown 工具进行编辑并直接上传。
python的markdown扩展开发
近期使用python的markdown写了一个文档小程序,由于需要用到一些额外的功能,所以就对markdown进行了一些简单的扩展,进而记录下编写的模板。直接贴代码:
#encoding=utf-8
##预处理器
from markdown.preprocessors import Preprocessor
class CodePreprocessor(Preprocessor):
def run(self, lines):
new_lines = []
flag_in = False
block = []
for line in lines:
if line[:3]=='!!!':
flag_in = True
block.append('<pre class="brush: %s;">' % line[3:].strip())
elif flag_in:
if line.strip() and line[0]=='!':
block.append(line[1:])
else:
flag_in = False
block.append('</pre>')
block.append(line)
new_lines.extend(block)
block = []
else:
new_lines.append(line)
if not new_lines and block:
new_lines = block
return new_lines
##后置处理器
from markdown.postprocessors import Postprocessor
class CodePostprocessor(Postprocessor):
def run(self, text):
t_list = []
for line in text.split('\n'):
if line[:5]=='<p>!<':
line = line.lstrip('<p>').replace('</p>', '')[1:]
t_list.append(line)
return '\n'.join(t_list)
##扩展主体类
from markdown.extensions import Extension
from markdown.util import etree
class CodeExtension(Extension):
def __init__(self, configs={}):
self.config = configs
def extendMarkdown(self, md, md_globals):
##注册扩展,用于markdown.reset时扩展同时reset
md.registerExtension(self)
##设置Preprocessor
codepreprocessor = CodePreprocessor()
#print md.preprocessors.keys()
md.preprocessors.add('codepreprocessor', codepreprocessor, '<normalize_whitespace')
##设置Postprocessor
codepostprocessor = CodePostprocessor()
#print md.postprocessors.keys()
md.postprocessors.add('codepostprocessor', codepostprocessor, '>unescape')
##print md_globals ##markdown全局变量
关于markdown扩展的深入内容,可以查看官方文档,不过没有例子,只是手册而已。但大体能知道有哪些内容组成,在结合上面的文件结构都是可以写出来的。下面是调用的代码:
#encoding=utf-8
import markdown
import markdowncode
text = '''''
!!!python
!
!def foo():
###title
'''
configs = {}
myext = markdowncode.CodeExtension(configs=configs)
md = markdown.markdown(text, extensions=[myext])
print md
主要扩展了2个功能:
一个是把形如:
!!!python ! !def foo(): ! return 'foo'
转换成:
<pre class="brush: python;"> def foo(): return 'foo' </pre>