Python中利用Scipy包的SIFT方法进行图片识别的实例教程
scipy
scipy包包含致力于科学计算中常见问题的各个工具箱。它的不同子模块相应于不同的应用。像插值,积分,优化,图像处理,,特殊函数等等。
scipy可以与其它标准科学计算程序库进行比较,比如GSL(GNU C或C++科学计算库),或者Matlab工具箱。scipy是Python中科学计算程序的核心包;它用于有效地计算numpy矩阵,来让numpy和scipy协同工作。
在实现一个程序之前,值得检查下所需的数据处理方式是否已经在scipy中存在了。作为非专业程序员,科学家总是喜欢重新发明造轮子,导致了充满漏洞的,未经优化的,很难分享和维护的代码。相反,Scipy程序经过优化和测试,因此应该尽可能使用。
scipy由一些特定功能的子模块组成,它们全依赖numpy,但是每个之间基本独立。
举个Debian系的Linux中安装的例子(虽然我在windows上用--):
复制代码 代码如下:
sudo apt-get install python-numpy python-scipy python-matplotlib ipython ipython-notebook python-pandas python-sympy python-nose
导入Numpy和这些scipy模块的标准方式是:
import numpy as np from scipy import stats # 其它子模块相同
主scipy命名空间大多包含真正的numpy函数(尝试 scipy.cos 就是 np.cos)。这些仅仅是由于历史原因,通常没有理由在你的代码中使用import scipy。
使用图像匹配SIFT算法进行LOGO检测
先上效果图:
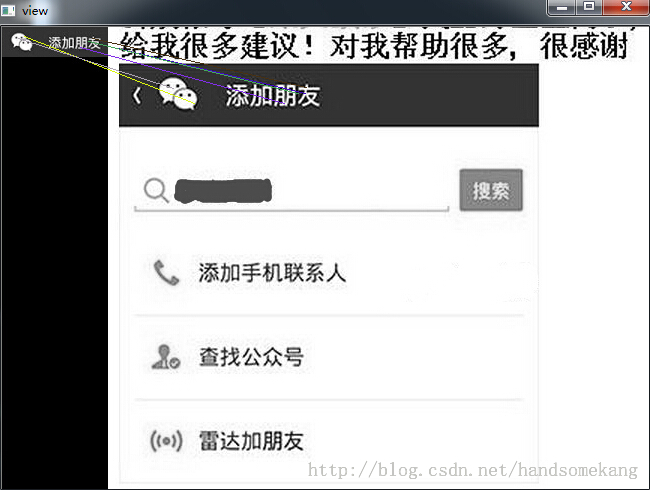
其中 是logo标识,
是logo标识,
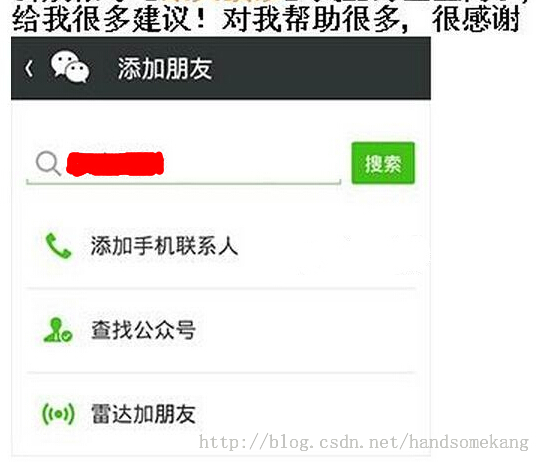
代码如下.
#coding=utf-8
import cv2
import scipy as sp
img1 = cv2.imread('x1.jpg',0) # queryImage
img2 = cv2.imread('x2.jpg',0) # trainImage
# Initiate SIFT detector
sift = cv2.SIFT()
# find the keypoints and descriptors with SIFT
kp1, des1 = sift.detectAndCompute(img1,None)
kp2, des2 = sift.detectAndCompute(img2,None)
# FLANN parameters
FLANN_INDEX_KDTREE = 0
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
search_params = dict(checks=50) # or pass empty dictionary
flann = cv2.FlannBasedMatcher(index_params,search_params)
matches = flann.knnMatch(des1,des2,k=2)
print 'matches...',len(matches)
# Apply ratio test
good = []
for m,n in matches:
if m.distance < 0.75*n.distance:
good.append(m)
print 'good',len(good)
# #####################################
# visualization
h1, w1 = img1.shape[:2]
h2, w2 = img2.shape[:2]
view = sp.zeros((max(h1, h2), w1 + w2, 3), sp.uint8)
view[:h1, :w1, 0] = img1
view[:h2, w1:, 0] = img2
view[:, :, 1] = view[:, :, 0]
view[:, :, 2] = view[:, :, 0]
for m in good:
# draw the keypoints
# print m.queryIdx, m.trainIdx, m.distance
color = tuple([sp.random.randint(0, 255) for _ in xrange(3)])
#print 'kp1,kp2',kp1,kp2
cv2.line(view, (int(kp1[m.queryIdx].pt[0]), int(kp1[m.queryIdx].pt[1])) , (int(kp2[m.trainIdx].pt[0] + w1), int(kp2[m.trainIdx].pt[1])), color)
cv2.imshow("view", view)
cv2.waitKey()